

こんにちはtetsuです。
今回はタイトルの通り、
Unsupervised Representation Learning by Predicting Image Rotationsという論文の紹介をします。
この論文では、画像の回転角度を予測するようにニューラルネットワークを学習させることで、教師なしで良い特徴量を得る方法を提案しています。
教師なしでの特徴量の学習のモチベーション
画像から良い特徴量を抽出することができるネットワークを学習することができれば、クラスタリングや類似画像検索、転移学習に利用することが可能です。
一般にそのような用途で用いられている訓練済みのネットワークはVGGやResNetだと思います。これらのネットワークは膨大なラベル付きの画像を用いて学習(教師あり学習)がおこなわれています。しかしながら、膨大なラベル付きの画像を用意するのは大変な手間がかかりますし、世の中に存在するラベル付けがされていない画像は学習に利用されないままです。ラベル付けされていない画像を用いた学習(教師なし学習)をすることができれば、ラベル付けの手間を省くことができますし、世の中に存在する画像を多く利用することができます。
提案手法
論文中で提案されている手法は至ってシンプルです。
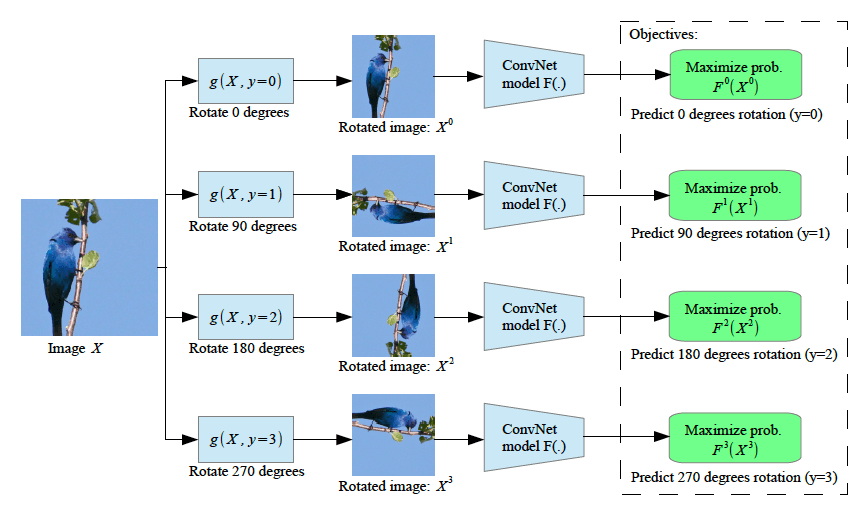
1枚の画像に対して回転画像を作り、それをネットワークの入力とします。論文中では、実験において画像分類の精度が最も良かった0°、90°、180°、270°の角度の組み合わせが使われています。ネットワークは入力された画像が何度回転しているのかを当てるように学習されていきます。例えば0°、90°、180°、270°の4つが回転角度として使われる場合には、このネットワークは4クラス分類を解くことになり、ネットワークの出力は各回転角度の確率です。
論文中に示されている提案手法の説明図が以下になります。
提案手法がなぜうまくいくのか?
このような非常にシンプルなアイデアで本当に良い特徴量を抽出するネットワークが出来上がるのかという疑問が湧いてきます。実験結果は最後に紹介するとして、なぜうまくいくのかについての根拠について説明します。
画像が何度回転しているかについてを正しく認識するためには、画像から”角度を判断するために見るべき物体がどこにあるのか”、”物体は何か”、”物体はどういう向きであるのか”を認識しなければいけません。このため、問題設定が簡単であっても、モデルは複雑なタスクをこなせるように学習をしていく必要があります。結果として学習を終えたモデルは良い特徴量を作り出すことができるという理屈です。
次の図はAlexNetを教師ありで学習させた場合(左図)と提案手法の教師なしで学習させた場合(右図)で、 各中間層の出力がどこに重きを置いているのかを示しています。この図の見方ですが、上部に示された入力画像に対して各中間層が着目している部分が明るく示され、着目していない部分は黒く示されています。左列から右列にいくにつれて、より深い層の着目している部分をあらわします。例えば右図の一番右の列をみると、教師なし学習であっても人間の頭や猫の目などを認識し、着目するような仕組みができあがっていることが確認されます。

また、学習によって得られたフィルター(AlexNetの第一層)についても論文中では言及されており、次の図のようになっています。教師ありの場合(左図)と提案手法(右図)ではフィルターに違いが出ており、提案手法のほうがよりバラエティ豊かになっています。

以上の話から、提案手法がうまくいきそうな気がしてきたのではないでしょうか。
実験結果
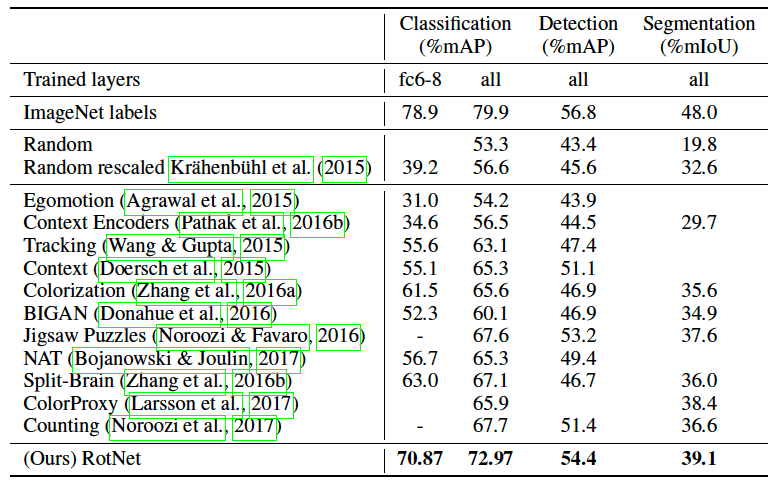
論文中では多くの実験結果が示されていますが、ここでは他手法との精度比較の例を1つ紹介します。
実験ではまずImageNetを学習データとしてAlexNetに与え、提案手法と比較対象の手法でそれぞれ事前学習をおこないます。そのあとPASCAL VOCデータセットを用いて分類問題用、物体検出用、領域分割用にそれぞれfine-tuningしていきます。
このようにして学習した提案手法と他手法の精度の比較が次の表になります。なお、分類問題のみはfine-tuningではなく、全結合層だけをPASCAL VOCデータセットを用いて学習している結果も載せてあり、それはClassificationの左列になります。ImageNet labelsはラベル付きのImageNetを用いて事前学習した結果をあらわしており、ImageNet labelsとRandom以外は事前学習は教師なしです。
各値は大きければより精度が高いことを示しますが、提案手法(一番下)は他の教師なしの手法よりも高い精度になっていることが確認されます。物体検出に関してはラベル付きのImageNetの画像を学習した場合とそれほど精度に差がありません。
以上の結果から、各問題において提案手法では高い精度になっており、良い特徴量の抽出が出来ていることが分かります。
最後に
今回は画像の回転を学習に利用した教師なし学習を紹介しました。
非常にシンプルなアイデアですが、精度が高くなかなか強力な手法ではないでしょうか。