

こんにちは、エンジニアのtetsuです。
Pandasでデータを処理しているときに、ここを並列計算させたら早くなりそうなんだけどなぁ、と思うことはありませんか?もしかしたら、Daskを使うことで望みの並列計算がおこなえるかもしれません。今回はDaskでのPandasのapplyの並列化の例を示していきます。
Daskとは?
Daskとは並列計算やOut-Of-Coreの処理が簡単にできるpythonのライブラリです。NumPyやPandasのデータを扱うことができますが、Dask内ではこれらのデータを分割して処理をおこなうことで、並列化を実現しています。
インストールは簡単で、pipで次のようにおこなえます。Anacondaにはデフォルトで入っているので、Anacondaを利用している場合にはインストールは不要です。
|
1 |
$ pip install dask |
Daskによるapplyの並列化
以下ではapply関数によるPandasのDataFrameの行ごとの処理を、Daskにより高速化する例を示します。
まず以下にPandasでのapplyの適用例を示します。
|
1 2 3 4 5 6 7 |
import pandas as pd def mysum(row): return row["x"] + row["y"] df = pd.DataFrame({"x": range(1000000), "y": range(0, -1000000, -1)}) sums = df.apply(mysum, axis=1) |
上記のコードを実行すれば、applyによって一行ずつxの列とyの列の和が計算されていきます。実際には、この和の計算にはapplyを使う必要は全くありませんが、簡単のためにこのような関数にしています。これらの計算は1プロセスでおこなわれます。これに対し、Daskを用いて2プロセスで並列計算をおこなう例が次のコードになります。
|
1 2 3 4 5 |
import dask.dataframe as dd from dask.multiprocessing import get ddf = dd.from_pandas(df, npartitions=2) sums = ddf.apply(mysum, axis=1, meta=('int')).compute(get=get) |
dd.from_pandasではPandasのDataFrameを受け取り、npartitionsに指定された数にDataFrameを分割します。計算機のコア数が許す限りは、この分割数で並列計算がされます。その次の行のddf.applyがDask用のapplyになっていますが、computeが実行されるまでは計算はおこなわれない仕組みになっています。また、computeの引数で与えているgetにはどういうスケジューラで処理をおこなうかを指定します。このケースではマルチプロセスで実行するように指定しています。
計算時間の比較
分割数を1~4として計算をおこなったときの各計算時間を以下に示します。ただし、分割数が1のときはDaskではなく、Pandasを用いた場合の計算時間になります。また、使用した計算機には4コア搭載されています。
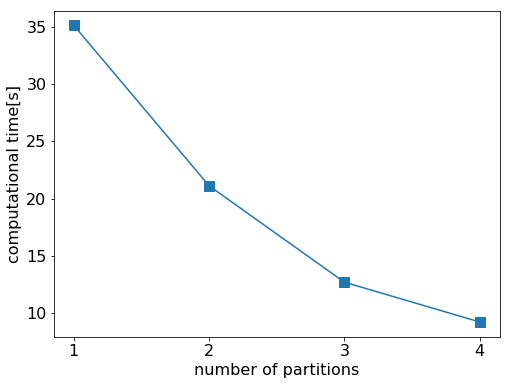
分割数を増やすことによって、ある程度きれいに計算時間がスケールしていることが確認できます。
終わりに
今回はDaskを用いた並列計算の例を示しました。非常に簡単に扱えるため、ぜひ活用していきたいですね。