

お初にお目にかかります。エンジニアのBBです。
このエントリーでは機械学習とは無縁の人生を送っていた人間(僕)がいざ機械学習を始めるにあたり試行錯誤していく過程がメインになっていきます。玄人の方は鼻で笑い、初学者の方はどうか参考にしていただけると幸いです。
レコメンドプログラムを作ろう
今回は初python、初機械学習に挑戦ということでおなじみブログ記事のレコメンドをするプログラムを作成したいと思います。ブログを読んでいるとして、その読んでいる記事に関連する記事を「おすすめ記事」みたいに表示する機能、よくありますよね。あれです。ここから詳細を説明していきます。
処理概要
ブログ記事レコメンドプログラムの処理概要をまとめるとこんな感じです。
手順1.ブログ記事を取得
手順2.テキストをクリーニング
手順3.形態素解析~特徴ベクトル作成
手順4.レコメンド記事出力
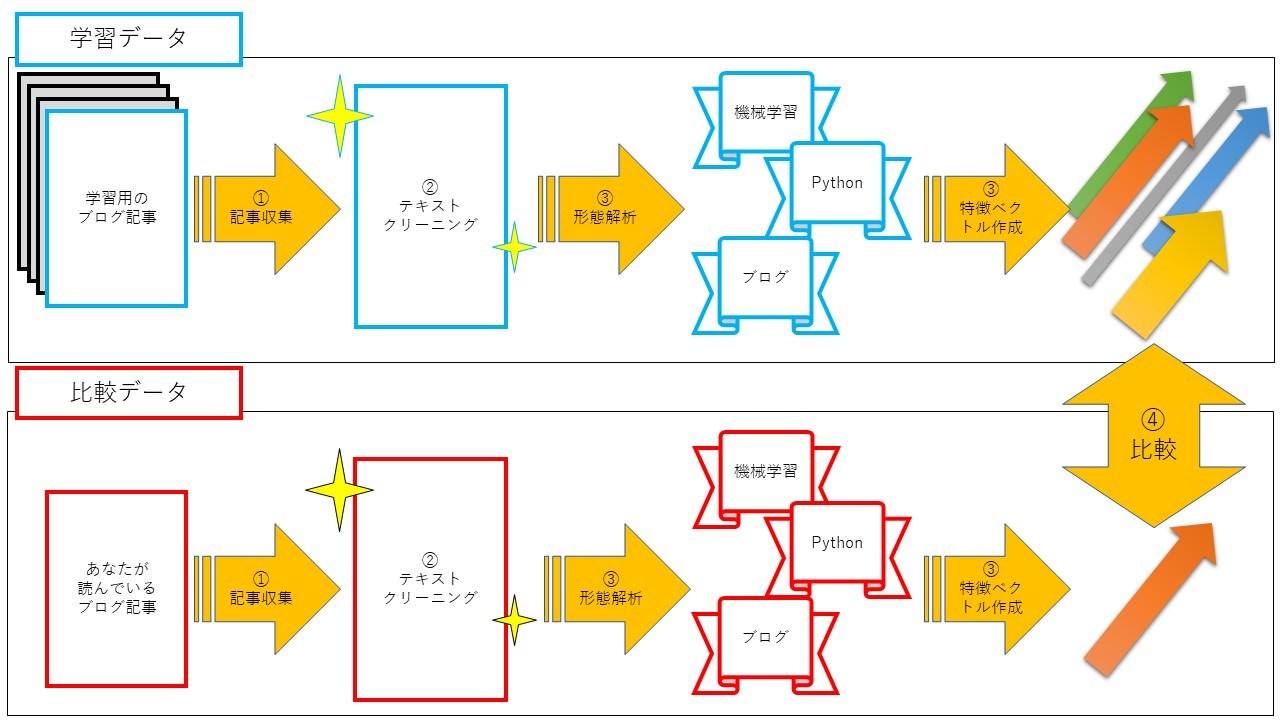
学習データとしてブログ記事を集めます。記事データはHTML形式なのでタグやリンクなど余計なデータがありますのでクリーニングをかけます。きれいになったテキストを単語に分け、記事ごとに特徴ベクトルを作成してためておきます。読者が読んでいるブログ記事からも同じように特徴ベクトルを取得し、最も近しい記事をおすすめ記事として出力します。ちなみに、おすすめ記事は手順1で集めたデータの中から決定されます。
ブログ記事を取得
まずは、学習データとしてブログ記事を大量に集めることが必要となります。どのブログをターゲットにするか迷ったのですが、エンジニア御用達のブログ「Qiita」ではブログ情報を取得するためのAPI(Application Programming Interface)を提供してくれていますのでありがたく使わせていただくことに。
また、APIを通したブログ記事の取得方法はこちらの記事を参考にさせていただきました。
ブログ記事は最近投稿された記事から6000記事程を取得しています。あまりたくさんの記事を一度に取得することは出来ないので100件ずつ小分けにして取得しています。データはJson形式で取得できます。項目はいろいろあるのですが、今回使用するのは以下の3項目です。
- body : 記事の中身です。この後これをいじくっていきます。
- title : 最終的におすすめ記事を表示するときに使います。
- url : titleと同じくおすすめの表示に使用します。
テキストをクリーニング
Qiitaの”body”データは親切なことにhtmlタグなどは省いたテキストになっているのですが、改行コードなどが含まれています。また、アルファベットを小文字に統一、記号の除去などこの後の処理がしやすいようにクリーニングをしてやることにします。また、記事内のサンプルコードも削除しておきます。
ちなみに”rendered_body”データにはhtmlタグが付加されていますので必要に応じてこちらを使用するとよいでしょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
# テキストクリーニング import re import csv import json import glob dir_name = '../data/' def clean_text(text): # 除去対象の記号 replace = '˗֊‐‑‒–⁃⁻₋−﹣-ー—―─━ー∼∾〜〰~±|' \ '!"#$%&\'()*+,-./:;?@[¥]^_`{|}~。、・「」' \ '!”#$%&’()*+,-./:;<=>?@[¥]^_`{|}〜。、・「」' text = text.lower() # 小文字変換 text = re.sub('https?:\/\/.*?[\\r\\n ]', '', text) # URLの除去 text = re.sub(r'[0-9]', ' ', text) # 半角数字の除去 text = re.sub(r'[0-9]', ' ', text) # 全角数字の除去 text = re.sub(r'', ' ', text) # htmlタグの除去 text = re.sub('\\n', ' ', text) # 改行の除去 text = re.sub('```.*?```', '', text) # コードの除去 for w in replace: print('w=', w) text = text.replace(w, ' ') return text def make_train_csv(f_name_contents, f_name_titles): path = '%sitems/*.json' % dir_name # 記事テキストデータ contents = [] # 記事タイトル、URL(レコメンド用) titles = [] url = [] for file in glob.glob(path): with open(file, 'rb') as f: json_data = json.load(f) # 記事テキストデータのクリーニングを実施 contents.append(clean_text(json_data['body'])) titles.append(json_data['title']) url.append(json_data['url']) with open('%s%s' % (dir_name, f_name_contents), 'w', encoding='UTF-8') as f_contents: writer = csv.writer(f_contents, lineterminator='\n') for i in range(len(contents)): writer.writerow([contents[i]]) with open('%s%s' % (dir_name, f_name_titles), 'w', encoding='UTF-8') as f_title: writer = csv.writer(f_title, lineterminator='\n') for i in range(len(titles)): writer.writerow([titles[i], url[i]]) def make_test_csv(f_name_content): with open('%stest.txt' % dir_name, 'r', encoding='UTF-8') as f: content = f.readlines() with open('%s%s' % (dir_name, f_name_content), 'w', encoding='UTF-8') as f_content: writer = csv.writer(f_content, lineterminator='\n') for i in range(len(content)): writer.writerow([content[i]]) if __name__ == "__main__": make_train_csv('contents.csv', 'titles.csv') make_test_csv('content_test.csv') |
最終アウトプットでおすすめ記事を出力したいので、クリーニング後のbodyデータ記事とは別に、タイトルとURLを持つファイルを出力しています。
MeCabを使った形態素解析~bag-of-wordsによる特徴ベクトル作成
形態素解析~特徴ベクトル作成はこちらの記事を参考にさせていただきました。
形態素解析とは文章を単語単位に分割し、品詞や内容を判別する処理のことを指します。今回、日本語にも対応した形態素解析フリーソフトのMeCabを使っています。MeCabをデフォルトのまま使用してもよいのですが、少し問題があります。MeCabは自身の持っている辞書をもとに文章を単語に分割しているのですが、その辞書に載っていない単語はうまく抜き出すことができないのです。例えば「機械学習についての入門記事です」という文章を形態素解析しようとしたとき、デフォルトのままだと分割結果はこんな感じです。
| 機械 | 名詞,一般,*,*,*,*,機械,キカイ,キカイ |
|---|---|
| 学習 | 名詞,サ変接続,*,*,*,*,学習,ガクシュウ,ガクシュー |
| について | 助詞,格助詞,連語,*,*,*,について,ニツイテ,ニツイテ |
| の | 助詞,連体化,*,*,*,*,の,ノ,ノ |
| 入門 | 名詞,サ変接続,*,*,*,*,入門,ニュウモン,ニューモン |
| 記事 | 名詞,一般,*,*,*,*,記事,キジ,キジ |
| です | 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス |
「機械学習」という意味のある塊が「機械」と「学習」に分割されてしまっています。これでは文章の特徴を正しく掴むことができませんね。そこで今回はmecab-ipadic-neologdを使っていきます。mecab-ipadic-neologdはMeCab用の拡張辞書で、ネット上の言語資源(はてなキーワードのダンプデータや日本全国駅名一覧のコーナーなどなど)を利用して固有表現をより的確に抽出することができます
。また、更新も頻繁に行われている為、最新の単語も登録されているそうです。
mecab-ipadic-neologdを使った結果がこちらです。
| 機械学習 | 名詞,固有名詞,一般,*,*,*,機械学習,キカイガクシュウ,キカイガクシュー |
|---|---|
| について | 助詞,格助詞,連語,*,*,*,について,ニツイテ,ニツイテ |
| の | 助詞,連体化,*,*,*,*,の,ノ,ノ |
| 入門 | 名詞,サ変接続,*,*,*,*,入門,ニュウモン,ニューモン |
| 記事 | 名詞,一般,*,*,*,*,記事,キジ,キジ |
| です | 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス |
今度は「機械学習」という塊で分割されていることがわかります。すばらしいですね!また、単語は品詞別に出力できますので名詞のみを対象としていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# MeCabを使った単語分割 import MeCab import csv # 拡張辞書mecab-ipadic-neologdを-dで指定 mecab = MeCab.Tagger('mecabrc -d /usr/lib/mecab/dic/mecab-ipadic-neologd') def tokenize(text): node = mecab.parseToNode(text) while node: if node.feature.split(',')[0] == '名詞': yield node.surface.lower() node = node.next def get_words_main(content): return [token for token in tokenize(content)] def get_word_contents(path): word = [] with open(path, 'r', encoding='UTF-8') as f_contents: rows = f_contents.readlines() for row in rows: word.append(get_words_main(row)) return word dir_path = '../data/' if __name__ == "__main__": # trainデータ作成 train_words = get_word_contents(dir_path + 'contents.csv') with open(dir_path+'words.csv', 'w', encoding='UTF-8') as f_train_words: writer = csv.writer(f_train_words, lineterminator='\n') for i in range(len(train_words)): writer.writerow(train_words[i]) # testデータ作成 test_words = get_word_contents(dir_path + 'content_test.csv') with open(dir_path+'words_test.csv', 'w', encoding='UTF-8') as f_test_words: writer = csv.writer(f_test_words, lineterminator='\n') for i in range(len(test_words)): writer.writerow(test_words[i]) |
形態素解析の準備が整いましたので特徴ベクトルを計算していきます。文章の特徴をベクトル化するためには文章を数値化していく必要があります。今回はbag-of-wordsという手法を用いて文章をベクトル化していきます。bag-of-wordsとは文章中にどの単語が何回現れるかをカウントしてその結果をベクトルとして扱う手法です。例えば①”pen this is a pen”と②”that is a pen”という2つの文章であれば以下のようにカウントされます。
| 単語 | ① | ② |
|---|---|---|
| this | 1 | 0 |
| that | 0 | 1 |
| a | 1 | 1 |
| pen | 2 | 1 |
このように数値化された結果をベクトルとして扱います。しかし、上の例の中には”a”のような有益な情報を持たない単語もカウントされてしまいます。比較に使用する単語は有益なものだけで構成したいので、比較対象の単語を選出する必要があります。Pythonではgensimというライブラリを使用してdictionaryという比較対象の単語一覧を作成することができます。dictionaryを作成する際にフィルターを設定することで不要な単語を削除することができます。今回は以下の設定でフィルターしています。設定値は出力結果をみてトライ&エラーで決めました。
- no_below:最低出現回数を指定します。出現頻度が少なすぎる単語を省きます。
- no_above:最高出現割合を指定します。出現頻度が多すぎる単語を省きます。
no_belowで特殊すぎる単語を無視することができます。また、no_aboveで頻出するが特に意味を持たない単語(先の例でいうと”a”のような)を無視することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# gemsimでの辞書作成 import csv from gensim import corpora dir_path = '../data/' words = [] with open(dir_path+'words.csv', 'r', encoding='UTF-8') as f_words: reader = csv.reader(f_words) for row in reader: words.append(row) dictionary = corpora.Dictionary(words) dictionary.filter_extremes(no_below=10, no_above=0.1) dictionary.save_as_text(dir_path+'dictionary.txt') |
最近傍法によるベクトル比較でレコメンド出力
さあ、下準備が整いましたので今回はこの記事のここまでの文章を使って学習データと同じように特徴ベクトルを計算します。この記事と学習データで計算した特徴ベクトルを使ってレコメンドまで出力してみましょう。形態素解析された単語一覧を見てみると一部不要なデータも残っていますが、「機械学習」や「レコメンド」などなんとなく記事の内容も把握することができます。※単語数が多いので掲載はやめておきます。
この単語データから特徴ベクトルを作成し、学習データのベクトルから最も近しいものを1つ選出、おすすめ記事として出力させます。ベクトルの比較は最近傍法という手法を用います。最近傍法は本来、与えられたベクトルに対し最も距離が短いベクトルの持つラベルを結果とするという分類手法ですが、今回はこの手法で最もベクトル同士の距離が短い記事をおすすめ記事として出力します。また、それぞれの記事が持つベクトルは長さが1になるよう正規化しています。ちなみに最近傍法を拡張したK近傍法という分類手法もよく使われます。最近傍法が最も近いデータ1つのもつラベルを結果として返すことに対し、K近傍法は近い順からK個のデータが持つラベルを投票して一番多いラベルを結果として返すのですが、今回は使用していません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# おすすめ記事出力 import csv import numpy as np from gensim import corpora, matutils from sklearn.neighbors import NearestNeighbors dir_path = '../data/' dictionary = corpora.Dictionary.load_from_text(dir_path+'dictionary.txt') train_words = [] with open(dir_path+'words.csv', 'r', encoding='UTF-8') as f_train_words: reader = csv.reader(f_train_words) for row in reader: train_words.append(row) test_words = [] with open(dir_path+'words_test.csv', 'r', encoding='UTF-8') as f_test_words: reader = csv.reader(f_test_words) for row in reader: test_words.append(row) titles = [] with open(dir_path+'titles.csv', 'r', encoding='UTF-8') as f_titles: reader = csv.reader(f_titles) for row in reader: titles.append(row) # trainデータの特徴ベクトル配列を作成 vectors = [] titles2 = [] for i in range(len(train_words)): tmp = dictionary.doc2bow(train_words[i]) vector = list(matutils.corpus2dense([tmp], num_terms=len(dictionary)).T[0]) # ゼロvectorを配列からはじく if np.linalg.norm(vector) != 0: vector = vector / np.linalg.norm(vector) vectors.append(vector) titles2.append(titles[i]) # testデータの特徴ベクトル作成 tmp_test = dictionary.doc2bow(test_words[0]) vector_test = list(matutils.corpus2dense([tmp_test], num_terms=len(dictionary)).T[0]) if np.linalg.norm(vector_test) != 0: vector_test = vector_test / np.linalg.norm(vector_test) nbrs = NearestNeighbors(n_neighbors=1, algorithm='ball_tree').fit(vectors) distances, indices = nbrs.kneighbors([vector_test]) print(indices[0]) print('distances =', distances) print('おすすめ記事:', titles2[int(indices[0])]) |
お待ちかねの出力結果としてこちらの記事がレコメンドされました!
- おすすめ記事タイトル: nagisa: RNNによる日本語単語分割・品詞タグ付けツール
- ULR:https://qiita.com/taishi-i/items/5b9275a606b392f7f58e
どうやら、この記事中盤に書かれている形態素解析の内容が強く反映されているようで単語分割や関連ツールの紹介記事が返ってきました。おすすめ記事としては問題ないような気がしますね!
まとめ
今回はbag-of-wordsを用いて文章から特徴ベクトルを計算し、最近傍法にておすすめの記事を出力することができました。
初心者ながら、何とかものにすることができましたが、何点か躓いた箇所がありましたのでまとめておきます。
サンプルの記事数
最初は1000記事で計算していましたが、最終的には6000記事まで増やしています。サンプルが少ないと、おすすめできる記事のバリエーションも減ってしまいますのでサンプル数は多いに越したことはないようです。
形態素解析に用いた辞書
記事内でも説明していますが、MeCabのデフォルト辞書で形態素解析を行っても最近の単語が反映されなかったり、単語が過剰に分解されてしまう為、可能な限りmecab-ipadic-neologdのような辞書を使用したほうが精度よく処理することができます。
dictionaryのフィルター
gensimを用いたdictionaryを作成する際に設定するフィルターの値で結果がかなり異なってきます。この値はサンプルに用いた記事数にも依存すると感じましたのでトライ&エラーで適切な値を探していきました。
処理内容についてはイメージできていたものの、実際にやってみるまで分からない課題が山盛りでなかなか手強い相手でしたが、楽しく作成することができました。今後もいろいろ作っていきたいと思いますのでよろしくお願いします!