

GoogleのOCR機能
GoogleのOCR機能をご存じでしょうか。
Googleドライブに画像を保存し、ファイルをGoogleドキュメントで開くと、テキスト化してくれます。
こんな感じです。
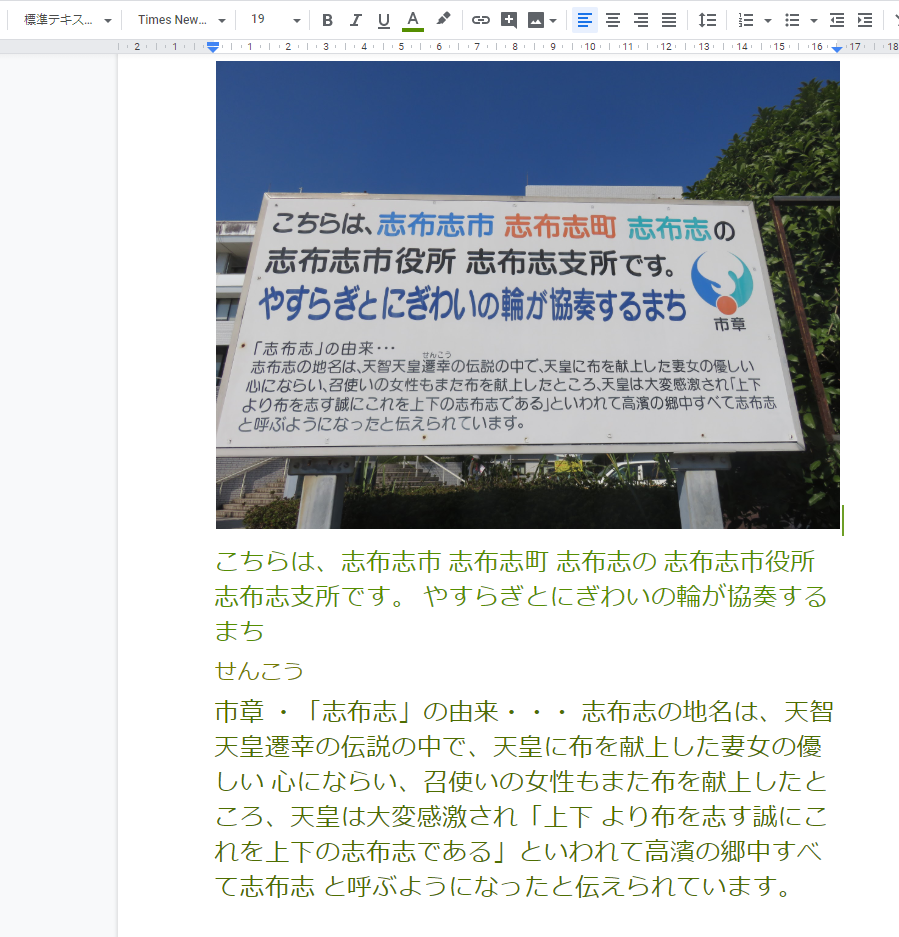
上が元画像、下が認識結果のテキスト情報です。
テキストにできると、翻訳したり、読み上げに使えたりするので便利ですよね。
Google Vision APIでOCR
便利なので、この文字認識の部分だけ、プログラムから実行したくなります。
画像を入力にし、認識結果の文字列を返す。この部分はGoogle Vision APIとして提供されています。
詳細はこちら
今回使うのは、任意の画像からテキストを検出、抽出する機能、TEXT_DETECTIONです。
APIを実行すると、認識結果の文字列だけではなく、認識結果の頂点の座標も返ってきます。
上述の詳細のページには、C#,Go,Java,Node.js,PHP,Python,Rubyのサンプルが記載されています。
私はC#の人なので、C#で実装します。
環境は以下の通りです。
環境
- Windows 10 Pro Version 1809
- .NET Core 2.2
- C# 7.3
- Visual Studio 2017 Professional
- Google.Cloud.Vision.V1 (1.5.0)←NuGetからインストール
Google公式サンプルに従って実装
サンプルに従って、実装してみます。
サンプルでは認識結果(Description)のみ表示していましたが、加えて、自動検出した言語(Locale)と、
認識結果の各頂点(BoundingPoly.Vertices)の座標も表示します。
こちらは、ドキュメントを参考にしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
using System; using System.Collections.Generic; using System.Linq; using Google.Cloud.Vision.V1; namespace GoogleVisionApiTrial { class Program { static void Main(string[] args) { Environment.SetEnvironmentVariable("GOOGLE_APPLICATION_CREDENTIALS", @"秘密鍵のファイルパス", EnvironmentVariableTarget.Process); // Load the image file into memory var image = Image.FromFile(@"読ませたい画像のパス"); DetectText(image); } private static void DetectText(Image image) { ImageAnnotatorClient client = ImageAnnotatorClient.Create(); IReadOnlyList<EntityAnnotation> textAnnotations = client.DetectText(image); foreach (EntityAnnotation text in textAnnotations) { //認識結果、言語、認識結果の各頂点を標準出力に表示 var coordinates = string.Join(",", text.BoundingPoly.Vertices.Select(v => $"({v.X},{v.Y})")); Console.WriteLine($"Description: {text.Description} Locale:{text.Locale} coordinates:{coordinates}"); } } } } |
※ちなみに、このImageは、「System.Drawing.Image」でなく、「Google.Cloud.Vision.V1.Image」です。
さて、動かすぞ!
の前に、まだ設定が必要です。
Google Cloud Consoleでの設定
Environment.SetEnvironmentVariable("GOOGLE_APPLICATION_CREDENTIALS", @"[秘密鍵のファイルパス]", EnvironmentVariableTarget.Process);
この部分に指定するファイルが必要になります。
秘密鍵を取得するために、Google Cloud Consoleでの設定が必要になります。(Googleのアカウントが必要です。)
- プロジェクトの選択→新しいプロジェクト
- プロジェクトで「Cloud Vision API」を有効に
- サービスアカウントの作成
- 鍵を作成→秘密鍵を含むファイルをダウンロード
ダウンロードしたファイルのパスを指定すれば、実行準備は終了です。
OCR実行!
読ませてみるのはこの画像です。
JRの特急券を、スマートフォンのカメラで撮影したものです。(96dpiのJPG)

この画像ファイルを、読ませたい画像のパスに指定して、実行。
まずは実行結果の1要素目のみを表示。
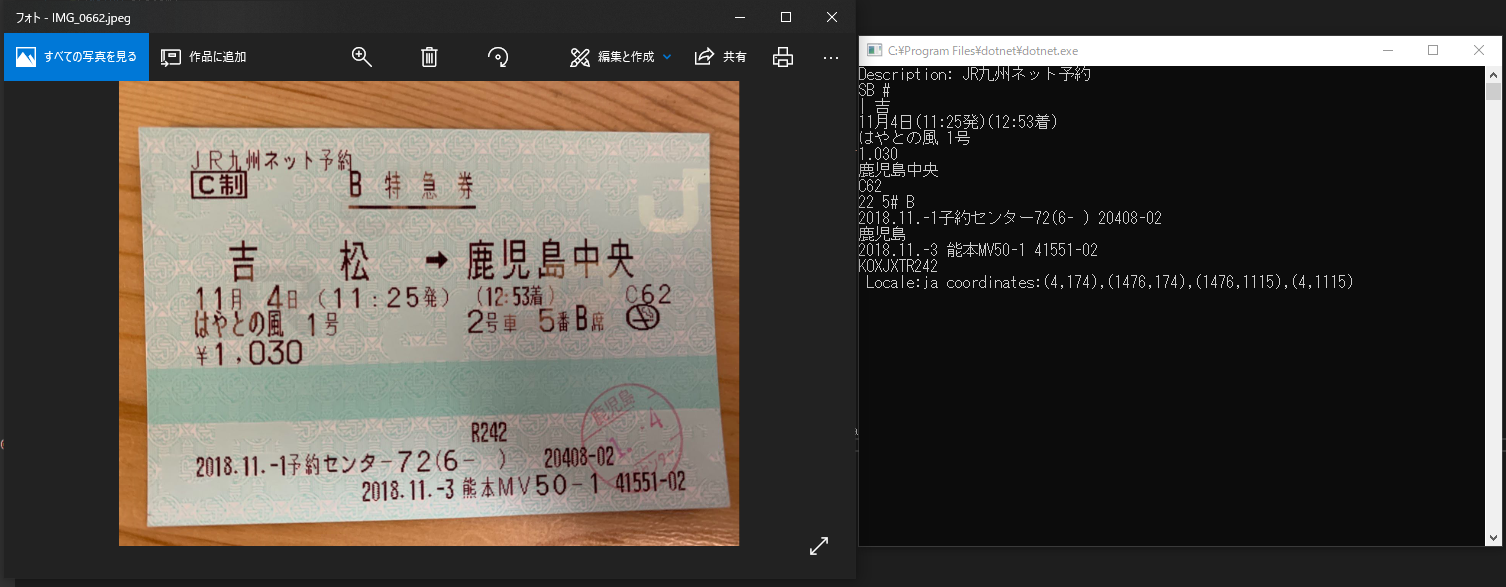
左が画像。右が標準出力の結果です。
Description: JR九州ネット予約
SB #
| 吉
11月4日(11:25発)(12:53着)
はやとの風 1号
1.030
鹿児島中央
C62
22 5# B
2018.11.-1子約センター72(6- ) 20408-02
鹿児島
2018.11.-3 能本MV50-1 41551-02
KOXJXTR242
Locale:ja coordinates:(4,174),(1476,174),(1476,1115),(4,1115)
認識結果(サマリー)
- 正読→日付(11月4日)、発車時刻(11:25発)、着駅(鹿児島中央)、到着時刻(12:53着)、列車名(はやとの風1号)、料金(1,030)
- 誤読→発駅(吉松 → 吉)、座席(2号車5番B席 → 22 5# B)
結構読めてます!
認識結果の続き(個別の認識結果)
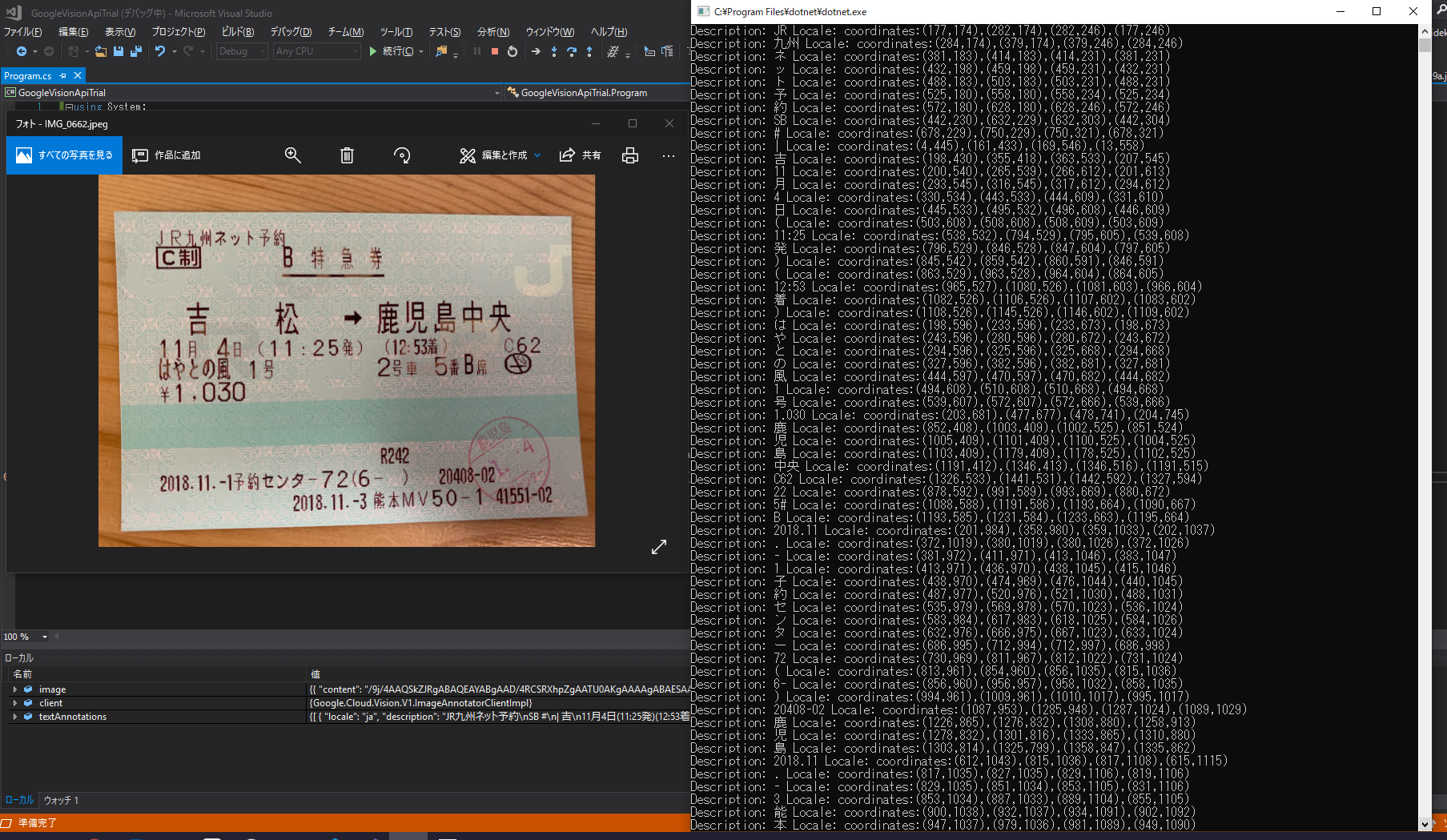
1要素目(textAnnotations[0])がサマリーで、2要素目以降(textAnnotations[i]、i > 0)は、
個別の認識結果が返ってきているようです。
Google Vision APIの他のメソッド
なお、今回使ったメソッドはDetectTextメソッドなのですが、注釈に以下の記載があります。
This method is suitable for an image with individual words; for more structured text, use DetectDocumentText(Image, ImageContext, CallSettings).
Google Vision APIが提供してくれているOCR機能にはDOCUMENT_TEXT_DETECTIONもあり、こちらは
高密度のテキストやドキュメントに応じてレスポンスが最適化され、ページ、ブロック、段落、単語、改行の情報が JSON に含まれます。
となっています。
認識結果をもとに何か加工したり、自然言語処理で精度を上げる場合には、情報が多いDOCUMENT_TEXT_DETECTIONの方がよさそうです。
こちらは別の機会に試してみます。