

エンジニアのtetsuです。業務では機械学習などを用いたデータ解析をおこなっています。
みなさんはkaggleという機械学習のコンペをご存知でしょうか?
データとそれに対して予測するべきお題が公開されており、どれだけ正確に予測できるかを世界中の人々が競うコンペです(例えば、タイタニックの乗客員の年齢、性別などをもとに誰が生き残ることができたかを予測するお題があります)。
そのkaggleで先日からサッカーゲームのFIFA18の選手データが公開されています。例えば、各選手の数値化した能力や年齢、市場価値などがデータに含まれます。このデータに対しては特に予測するべきお題が設定されていないのですが、選手の能力値などから市場価値を予測するということをやってみたいと思います。
予測のための道具として、最近kaggleでも使われているLightGBMを使用します。LightGBMは勾配ブースティング法というアルゴリズムを従来よりも高速に実装したライブラリで、マイクロソフトが2016年末に公開しました。
以下ではFIFA18の選手データとLightGBMについて軽く説明した後、実際の推定までの流れを説明してきます。
FIFA18の選手データ
肝心のFIFA18のデータは次のページで公開されています。downloadにはkaggleのアカウント登録が必要です。
FIFA 18 Complete Player Dataset
downloadしなくとも、どのようなデータなのかは「Data」のタブから確認できます。
csvファイルの1行が1人の選手データをあらわし、「名前」、「年齢」、「国籍」、「クラブ名」、「市場価値」などの情報や、「スタミナ」、「ボールコントロール」などの選手の能力を数値化したものが記載されています。
今回は前述したように、各選手のデータから市場価値を予測していきます。予測するために必要そうな次のデータを使うことにします。
- 年齢
- 所属クラブ
- 能力
LightGBMについて
LightGBMは勾配ブースティング法を高速に実装したライブラリです。また、高速であるだけではなく精度も良いです。LightGBMでは回帰問題(今回の市場価値の推定はこれに該当)、分類問題を解くことができるほか、ランク学習にも対応しています。勾配ブースティング法を実装したライブラリとしては他にXGBoostというものがあります。XGBoostも従来の勾配ブースティング法を実装したライブラリより高速だったのですが、LightGBMはそれよりもさらに高速化されています。計算時間の比較はここを参照してください。
ディープラーニングではCPUではなくGPUを使うことで学習を高速におこないますが、LightGBMでもGPUを使って学習をおこなうことができます。GPUを用いてより高速化できる点もLightGBMの特徴の一つです。ただし、今回はGPUを使う必要がない程度のデータの規模ですので、CPUを使って学習をおこないます。
なお、LightBGMやXGBoostで実装されている勾配ブースティング法の詳細などはここでは割愛します。
市場価値の推定までの流れ
次に市場価値の推定までの流れについて述べていきます。なお以下の処理はすべてpythonを使っています。データの読み込みや整形にはpandasを使っています。
データの整形
まずはデータの整形をおこないます。整形って何をするの?と思うかもしれませんが、そもそも素のデータには次の問題(問題というと大げさですが)があります。
- 選手の各ポジションの得意・不得意を数値化したデータがあるが、GKの選手に関してはGKのポジション以外は空欄になっている(GKの選手以外は全てのポジションに何かしらの値が入っています)
- 選手データの更新が行われたところには80+3や80-3のような足し算、引き算が含まれる(80が更新前の値で+3や-3が更新分のようです)
- 市場価値は「€50M」や「€50K」の形式の文字列になっていて、数値ではない
- 市場価値の値が選手によって大きく異なる(100Mユーロから0ユーロまで)
- 所属クラブ名をそのままLightGBMで扱うことはできない
これら5つの問題は、次のように変換する処理によって対処します。
- 空欄は0におきかえる
- 80+3や80-3は演算結果の83や77におきかえる
- ユーロは取り除き、€50Mは50000000、€50Kは50000のように数値におきかえる
- 市場価値の値に対してlogをとった値におきかえる
- 所属クラブの項目については各クラブ名を次のように数値におきかえる
Real Madrid CF→0
FC Barcelona→1
Paris Saint-Germain→2
︙
所属クラブのように0だったらReal Madrid CF、1だったらFC Barcelonaをあらわすといった対応関係がある変数をカテゴリ変数といいます。例えば男性だったら0、女性だったら1となる変数があった場合、これもカテゴリ変数です。注意点として、pandasを使って上記の処理をおこなった場合には所属クラブの列の型をcategory型(pandas固有の型)に変換する必要があります。これによってLightGBMに明示的にカテゴリ変数だと教えてあげます。
学習データ、テストデータ
機械学習では一般にデータを学習データとテストデータにわけます。学習データからデータの特徴を捉えるように学習をおこない、学習が上手くいったのかどうかをテストデータを用いて評価します。ここでも同様に全部で17981人分の選手データを学習データ16182人、テストデータ1799人のように分割します。
LightGBMによる学習
LightGBMで学習をおこなうときには色々なパラメータの値を決めることができます。パラメータの意味についてはここを参照して下さい。良いパラメータの値を求めて、それを使用することもできますが、簡単のために今回はパラメータを決め打ちします。
LightGBMを使う部分は非常に簡単で、次のコードで学習できます。ただしtrain_xとtrain_yはそれぞれ訓練用の整形済みの選手データ、市場価値をあらわします。test_xとtest_yはそれぞれテスト用の整形済みの選手データ、市場価値をあらわします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import lightgbm as lgb train_data_set = lgb.Dataset(train_x, train_y) test_data_set = lgb.Dataset(test_x, test_y, reference=train_data_set) params = { 'boosting_type': 'gbdt', 'objective': 'regression_l2', 'metric': 'l2', 'num_leaves': 40, 'learning_rate': 0.05, 'feature_fraction': 0.9, 'bagging_fraction': 0.8, 'bagging_freq': 5, 'lambda_l2': 2, } gbm = lgb.train(params, train_data_set, num_boost_round=200, valid_sets=test_data_set, early_stopping_rounds=10 ) |
LightGBMによる推定
テストデータに対する市場価値の推定値は次で計算できます。
|
1 |
y_pred = gbm.predict(test_x, num_iteration=gbm.best_iteration) |
推定結果
| 正解 | 推定値 |
|---|---|
| 4400000 | 4193154 |
| 875000 | 786408 |
| 600000 | 577723 |
| 1900000 | 1655905 |
| 675000 | 663385 |
一見、それほど間違っていない推定値になっているようです。
テストデータ1799人分の推定値に対して相対残差(この値が小さいほど良い)を計算した結果を以下に示します。一つの点が一人分の推定値の相対残差をあらわしていて、右にいくほど正解値が大きくなるようにソートをしています。
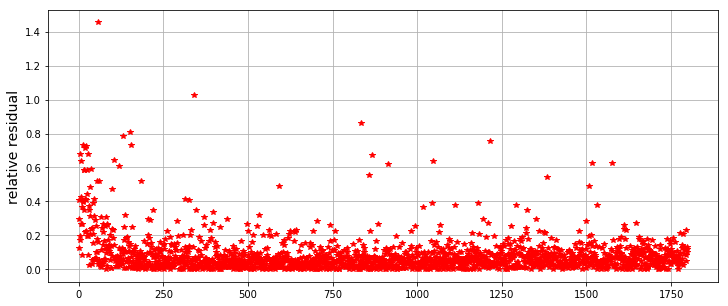
大体のデータに対しては相対残差は0付近に集まっていますが、ぽつぽつと比較的精度が悪い推定値があります。また左端(正解値が小さい)に精度が悪い推定値が多くなっています。はっきりとしたことは言えませんが、もしかすると市場価値をlogで変換していることが悪影響を及ぼしているのかもしれません。
まとめ
今回はFIFA18のデータでの選手の市場価値の推定について説明しました。市場価値の推定以外にも色々とお題を考えることができそうな面白いデータじゃないでしょうか?
また、推定に用いたLightGBMはこれからますます人気になっていくライブラリではないかと個人的には思っているので、興味を持たれた方はぜひ試していただきたいです。