

はじめに
ある業務でファイルのレイアウト解析を行うことになった。その際に検証したPythonライブラリ「Layout-Parser」の使い方を説明する。
インストール
今回の動作検証は、Windows11のWSL(Ubuntu-22.04)上で行った。また、Pythonの仮想環境はpyenv+poetryを用いて構築した。インストール時の一連のコマンドは以下の通りである。
|
1 2 3 4 5 6 7 |
$ sudo apt install liblzma-dev $ pyenv install 3.10.6 $ pyenv local 3.10.6 $ python -m venv .venv $ poetry init $ poetry add torchvision $ python -m pip install 'git+https://github.com/facebookresearch/detectron2.git' |
一番最後にインストールしているdetectron2については、poetryを用いたインストール方法が分からなかったのでpipで行った。Layout-Parserの詳細は、こちらを見てほしい。
コード
さて、サンプルコードにある以下のコードを実行してみる。
|
1 2 3 4 5 |
import layoutparser as lp model = lp.Detectron2LayoutModel('lp://PubLayNet/faster_rcnn_R_50_FPN_3x/config', extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8], label_map={0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}) |
すると以下のエラーが出る。
|
1 |
AssertionError: Checkpoint /home/kumada/.torch/iopath_cache/s/dgy9c10wykk4lq4/'model_final.pth not found! |
このエラーについてググるといくつかヒットするページがある。今回は以下のように解決した。どのサイトを参考にしたのかはうかつにも記録に残していなかったので不明である。
- ~/.torch/iopath_cache/s/dgy9c10wykk4lq4の下にある訓練済みモデル(ダウンロードされたもの)「’model_final.pth?dl=1’」をコピーして「model_final.pth」を同じフォルダ内に作る。
- ここにアクセスし、上のモデルに対応するyamlファイルをダウンロードする。
- 以下のコードに置き換える。
12345678YAML_PATH = "/home/kumada/data/layout_parser/config.yml"MODEL_PATH = "/home/kumada/.torch/iopath_cache/s/dgy9c10wykk4lq4/model_final.pth"model = lp.Detectron2LayoutModel(YAML_PATH ,MODEL_PATH ,extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],label_map={0: "Text", 1: "Title", 2: "List", 3: "Table", 4: "Figure"},)
これで動くようになる。検証に使ったコードは以下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
import glob import os from typing import Any import cv2 import layoutparser as lp # type: ignore import numpy as np # 画像のあるフォルダへのパス INPUT_DIR_PATH = "/home/kumada/data/layout_parser/2402.17764/" # 各領域の表す枠に色を付ける。 COLORS = { 0: (255, 0, 0), 1: (0, 255, 0), 2: (0, 0, 255), 3: (255, 255, 0), 4: (255, 0, 255), 5: (0, 255, 255), 6: (127, 0, 0), } # 訓練済みモデルへのパス # _/_/_/ lp://PrimaLayout/mask_rcnn_R_50_FPN_3x/config YAML_PATH = "/home/kumada/data/layout_parser/config_1.yaml" MODEL_PATH = "/home/kumada/.torch/iopath_cache/s/h7th27jfv19rxiy/model_final.pth" LABEL_MAP = { 1: "TextRegion", 2: "ImageRegion", 3: "TableRegion", 4: "MathsRegion", 5: "SeparatorRegion", 6: "OtherRegion", } # レイアウト分析後の画像を保存するフォルダへのパス OUTPUT_DIR_PATH = "/home/kumada/data/layout_parser/layouted_images_2402.17764/" def recognition_each_regions(image_: np.ndarray, model_: Any) -> np.ndarray: layout = model_.detect(image_) types = set() for block in layout: types.add(block.type) blocks = {} for value in LABEL_MAP.values(): print(value) blocks[value] = lp.Layout([b for b in layout if b.type == value]) # type: ignore for key, value in blocks.items(): print(f"the number of {key} blocks: {len(value)}") for i, (key, value) in enumerate(blocks.items()): print(i, key) color = COLORS[i] for block in value: x1, y1, x2, y2 = block.coordinates cv2.rectangle( image_, (int(x1), int(y1)), (int(x2), int(y2)), color, 2, ) text_position = (int(x1), int(y2) + 20) cv2.putText( image_, f"{key}: {block.score:.2f}", text_position, cv2.FONT_HERSHEY_SIMPLEX, 1.0, color, 2, ) image_ = cv2.cvtColor(image_, cv2.COLOR_RGB2BGR) return image_ if __name__ == "__main__": # 訓練済みモデルを読み込む model = lp.Detectron2LayoutModel( # type: ignore YAML_PATH, MODEL_PATH, extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.9], label_map=LABEL_MAP, ) print(type(model)) # フォルダ内の画像を拾う。 input_paths = glob.glob(os.path.join(INPUT_DIR_PATH, "*.jpg")) input_paths = sorted(input_paths) print(f"the number of inputs: {len(input_paths)}") for path in input_paths: print(path) image = cv2.imread(path) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # レイアウト分析を行う。 image = recognition_each_regions(image, model) # 結果を保存する。 file_name = os.path.basename(path) output_path = os.path.join(OUTPUT_DIR_PATH, file_name) print(output_path) cv2.imwrite( output_path, image, ) |
結果
今回使用した訓練済みモデルは、ファイル内から以下の領域を検出する。
- TextRegion(赤)
- ImageRegion(緑)
- TableRegion(青)
- MathsRegion(黄)
- SeparatorRegion(マジェンタ)
- OtherRegion(シアン)
最近話題になった論文「BitNet b1.58」の数ページをレイアウト分析した結果を示す。

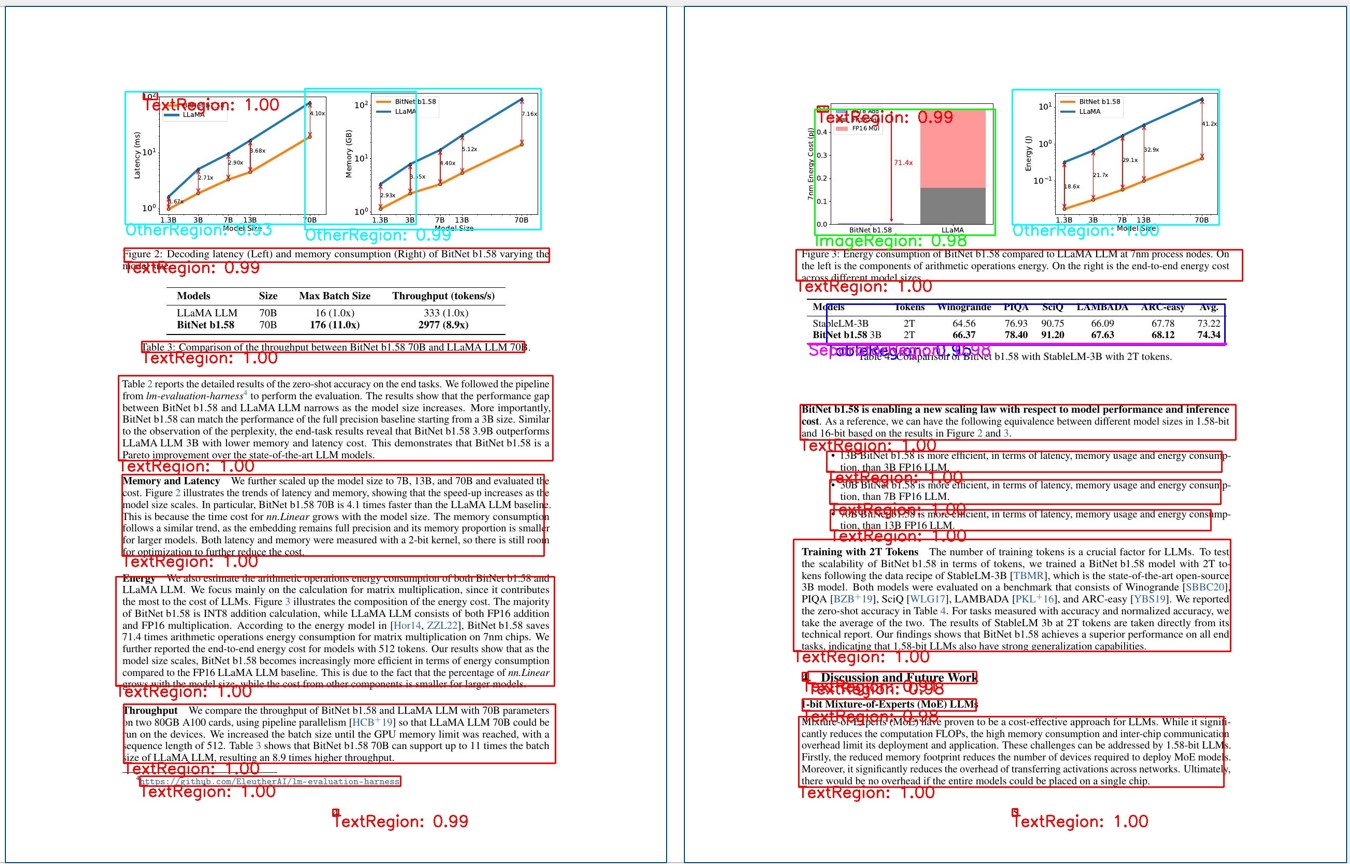
結果を見渡すと
- テキスト領域(赤色)は概ね取れている。
- 上段右図では数式(黄色)が取れている。
- 下段左図からはグラフがOtherRegion(シアン)として取れている。
- 下段右図からは表(青色)が取れている
- 上段左図と下段右図にある太い横棒がセパレータ(マジェンタ)として取れている。
かなり精度良く各領域が取れていると思う。
まとめ
今回は、業務関係で検証したPythonライブラリ「Layout-Parser」を紹介した。ライセンスがApache License 2.0なので商用利用は可能である。