

はじめに
2025年12月にAppleが、1枚の画像から3D Gaussian Splatting(3DGS)を生成するエンジンを公開した。名前は「SHARP」である。安価なGPU(VRAM6GB程度)を用いて、数秒で計算できるのが特長である。また、商用利用可能かつ、改変再配布可能なライセンス形態を持つ。今回は、このSHARPを紹介する。
そもそも3DGSとは?
3DGSとは点群やポリゴンとは異なる新しい3D表現方法である。簡単に説明すると以下のようになる(下図参照)。
- 3D空間内にたくさんの楕円体(3Dガウス関数)を配置する。
- 各楕円体には属性(位置、広がり、向き、色、透明度)が与えられる。
- 楕円体の数と各楕円体が持つ属性は、最適化計算(後述)により決定される。
- 任意の視点から、このたくさんの楕円体を見ると、任意視点から見た3D物体の画像を表現できる。
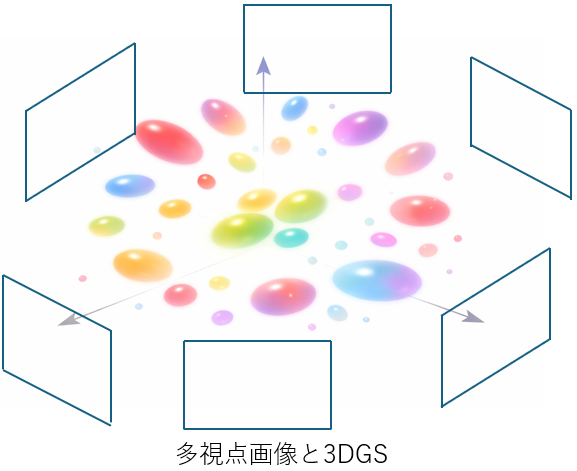
上記を実現するには、あらかじめ撮影された多視点画像が必要になる。この多視点画像を再現できるように最適化計算を行い、適切な場所に、適切な属性を持つ楕円体を置くことになる。ここで大切なことは、3DGSの計算には深層学習を使わないという点である。すべての楕円体の属性と位置を決めたあと、3DGSから任意視点の画像を作る手順は以下の通りである。
- 画像平面(カメラの位置)を決める。
- 各楕円体を、カメラ視線方向の深度でソートする。
- 各楕円体を画像平面に射影し、楕円(2D)を得る(下図参照)。
- ソートした順に(画像平面に近い方から奥に向かい)アルファ合成を行い、各画素の色を決める。

こちらに、論文著者らの公式サイトがあり、デモ映像を見ることができる。3DGSを描画するには専用のViewerが必要になる。例えばこれがある。
ここで説明した3DGSを、SHARPの3DGSと区別するため「オリジナルな3DGS」と呼ぶことにする。
SHARPとオリジナルな3DGSとの違い
SHARPは、深層学習を用いて3DGSを予測する手法である。3DGS作成時の、オリジナルな手法との違いは以下の通り。

上の表にある「SfM」とはStructure from Motionのことであり、多視点画像からカメラ姿勢を算出する手法である。COLMAPと呼ばれるツールを使うことが多い。ソースコードは、ここにある。
SHARPの大まかなロジック
最初に、一枚の画像を入力してから3DGSを作成するまでのニューラルネットワークの構成を以下に示す。原論文から抜粋した。
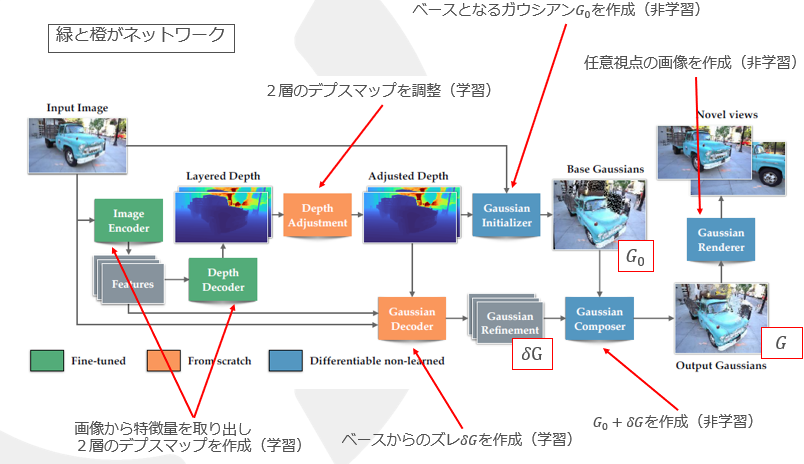
左上のInput Imageが入力画像である。そのあと、4つのニューラルネットワーク(緑と橙)を経て3DGS( )が作られる。そのあと、
)が作られる。そのあと、 を用いて、右上のNovel views(任意視点の画像)が描画される。
を用いて、右上のNovel views(任意視点の画像)が描画される。
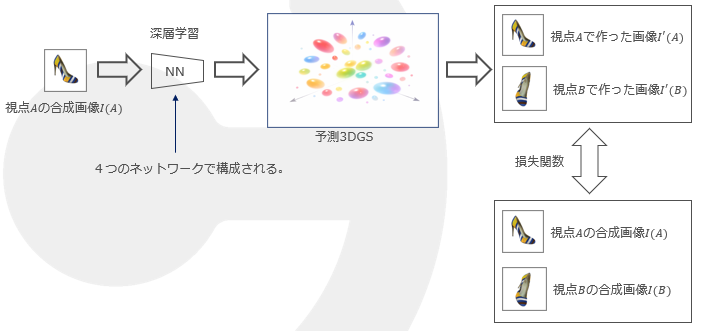
下図に、SHARPの学習時フローを示す。図中の「NN」が上のネットワーク構造に相当する。最初に合成画像(カメラ位置も既知)を使い教師あり学習を行う。
そのあと、実際の撮影画像を使い自己教師あり学習を行う。
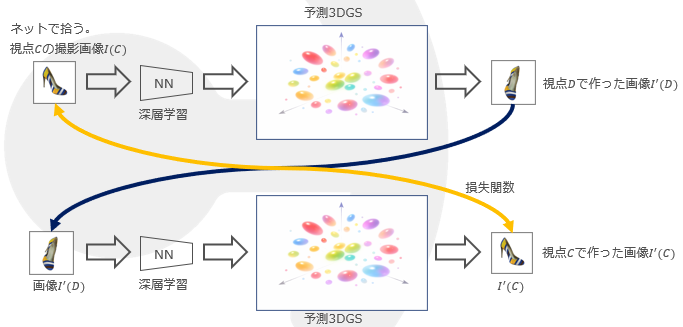
最初に3Dとして「何が正しいのか」を合成画像を使い教え、次のステップで実際の撮影画像を使い「実世界の見た目」に適応させる。
実験
SHARPの公式サイトにあるソースコードを使い、3枚の画像から3つの3DGSを作成した結果を以下に示す。動作環境は以下の通り。
- AWS EC2 g4dn.xlarge
- CPU: Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
- RAM: 16GB
- GPU: Tesla T4
- VRAM: 16GB
ここに掲載する3DGSの動画は、ブログの容量制限のため、動画サイズを10分の1に落としてある。実際にはもう少し画質は良い。
実験1
最初の画像(引用元)は以下である。画像サイズは6000×4000。

SHARPから作成した3DGSを動画で示したのが以下である(処理時間30秒程度)。
実験2
次の画像(引用元)は以下である。画像サイズは4928×3280。

SHARPから作成した3DGSを動画で示したのが以下である(処理時間は30秒程度)。
実験3
最後の画像(引用元)は以下である。画像サイズは4928×3280。

SHARPから作成した3DGSを動画で示したのが以下である(処理時間は30秒程度)。
まとめ
Apple社は、他のテック企業(Google、Microsoft、Meta、Amazonなど)と異なり生成AIに力を入れていない(最近、GoogleのGeminiを採用すると発表があった)。そのため、最近では影が薄いが、今回SHARPという面白いアルゴリズムをオープンソースとして公開した。自社で開発しているVision ProやiPhone搭載の写真アプリなどで使われているのかもしれない。
SHARPは1枚の画像から3DGSを作るため、オリジナルな3DGSと比べれば任意視点画像のクオリティは劣るが、原論文にも記載があるようにSHARPの目標は「元の画像から少し視点を動かした範囲」を自然に見せることである。そして、それを「短時間・低リソース・低コスト」で実現している点は注目に値すると思う。