

はじめに
「大文字・小文字を区別せずに検索したいんだけど。。。」といった要望ってわりとあります。
データがきれいに入っていれば(例えば、小文字にそろっている)、検索条件を小文字に置換した上での検索処理とすれば問題ないのですが、データが不ぞろい(大文字・小文字が混在)となっている場合はそうはいきません。
例えば、以下のことをやりたい、となった場合の対応について考えてみましょう。
【やりたいこと】
- 商品コードをアルファベット大文字小文字の区別無しに検索したいが、どうすればよいか。
- 商品コードは、商品コードマスタのテーブルに登録されている。
【現状】
- 商品コードはアルファベットと数字と記号で構成されている(例:ABC-1234)
- 商品コードの入力機能ではアルファベット大文字小文字をどちらも許容している。
- 業務上、商品コードのアルファベット大文字と小文字は区別しないため、2のケースでもヒットするようにしたい
- ABC-1234のコードに対して、abc-1234の検索条件を与えてもヒットしない
実現したい内容とDBMSによっては、照合順序の設定次第で特に何もしなくても実現できてしまうかもしれません。
以下でそれを検証してみます。
PostgreSQLでやってみる
まずは、PostgreSQLにデータを入れてやってみましょう。
全件を抽出。select * from shohin
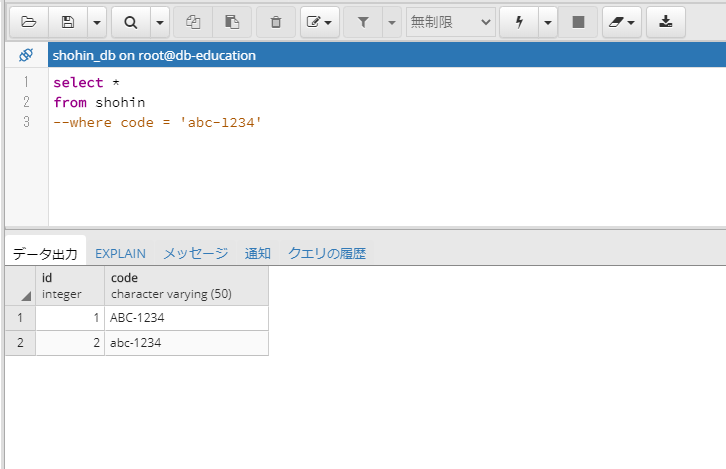
大文字のコードと、小文字のコードが抽出されました。
では、検索条件を指定しましょう。select * from shohin where code = 'abc-1234'
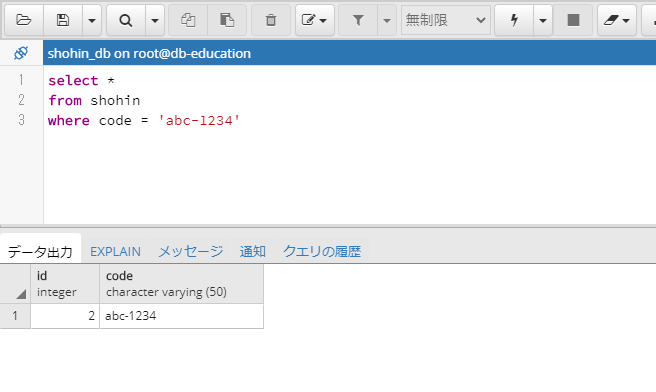
小文字の方のみ抽出されました。
PostgreSQLの場合、ILIKE演算子を使えば実現できます。select * from shohin where code ILIKE('abc-1234')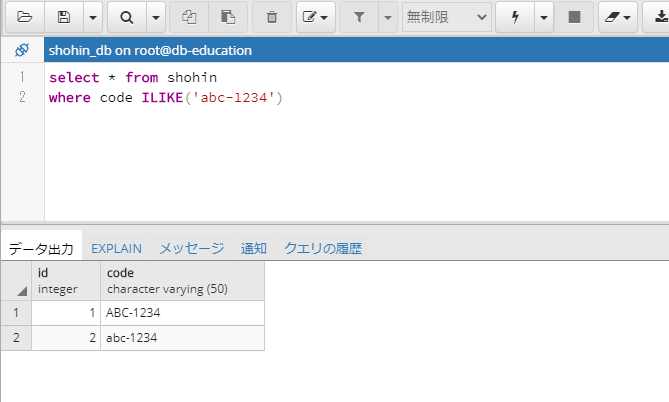
SQL Serverでやってみる
次に、SQL Serverにデータを入れてやってみましょう。
全件を抽出。SELECT * FROM [dbo].[shohin]
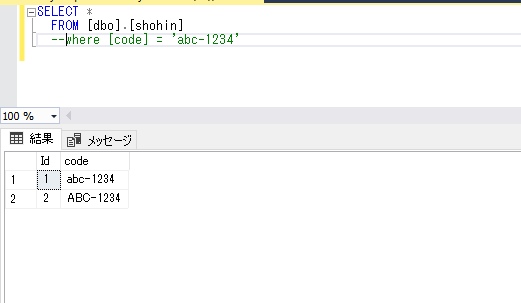
PostgreSQLと同様に、大文字のコードと、小文字のコードが抽出されました。
では、検索条件を指定しましょう。SELECT * FROM [dbo].[shohin] where [code] = 'abc-1234'
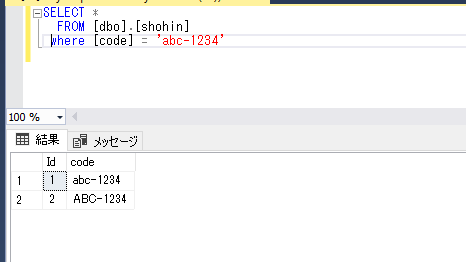
あれ。。。大文字の方も抽出されました。
特に何もしなくても、やりたいことが実現できてしまいました。
照合順序の設定を確認する
SQLServerの照合順序を確認しましょう。(データベースはデフォルト設定でインストールしました)
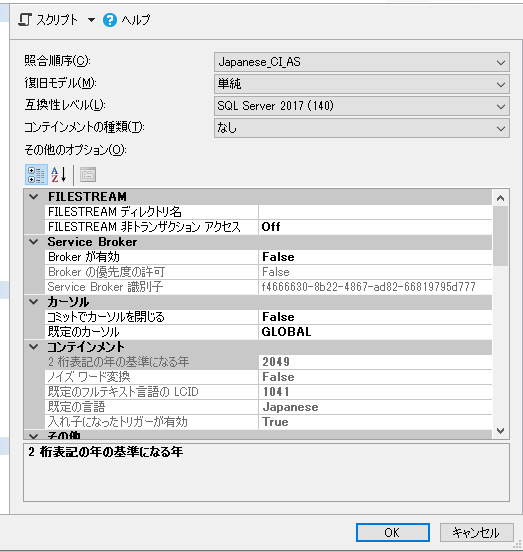
Japanese_CI_KSとなっています。この意味は以下の通りです。
Japanese→ ロケールCI→ Case-Insensitive(大文字・小文字を区別しない)KS→ Kana-Sensitive(ひらがな・カタカナを区別する)
「大文字・小文字を区別しない」の設定が効いているため、大文字・小文字のどちらも抽出されました。
SQLServerには他に「文字幅を区別しない」(全角・半角を区別しない)といった設定もあります。その他、詳しくは「照合順序と Unicode のサポート(MicrosoftのSQLドキュメントより)」まで。
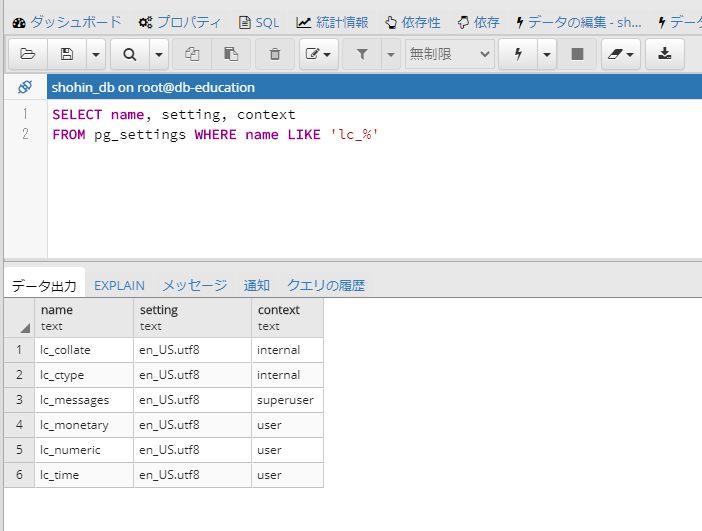
また、PostgreSQLでの照合順序は以下を指します。
照合順序機能は、ソート順番と列ごともしくは操作ごとのデータの文字区別の振る舞いを指定することを可能にします。 これにより、作成後のデータベースのLC_COLLATEとLC_CTYPEの設定が変更できない制限が緩和されます。
照合順序サポート(PostgreSQL 11.5文書) より引用
LC_COLLATE→文字列の並び換え順(この環境ではen_US.utf8でした)LC_CTYPE→文字の分類(この環境ではen_US.utf8でした)
最後に
DBMSによっては、SQLを変えることなく、すでにそういう照合順序の設定になっていて、やりたいことが実現できているケースもあります。(良くも悪くも)
これまで数々のシステムに携わっていましたが、意外と照合順序に気を遣わず初期セットアップをしてしまい、後から変えられずに困るケースがありました。
上述のとおり、検索結果が思った通りにならないケースもありますので、気を付けるようにしてみてもらえると幸いです。