

はじめに
今回は、Googleが最近リリースした画像生成AI「Nano Banana」を紹介する。Nano Bananaは、Google社内でのコードネームであり、正式名称は、Gemini-2.5-flash-imageである。このモデルは、以下の能力が高いと言われる。
- 人物・対象の一貫性維持能力
- 自然言語指示による編集能力
- 部分編集能力
- 複数画像の融合と合成能力
ChatGPT5と比較しつつ検証を行った。結論を先に言うと、上の各項目の能力は確かに高いが、日本語のレンダリング能力は高くない。
サンプル1
Nano Banana
最初に、Nano Bananaが生成した画像を以下に示す(①から⑤までの画像)。

与えたプロンプトは以下の通り(プロンプトの番号と上の画像の番号は対応する)。
- 最初の画像に移っている男性(上図の左上)に、2枚目の男性(上図の左下、著作者:freepik)が来ている服を着せてください。
- 上の画像の男性にこの帽子(上図の①の下)を被せてください。
- この男性を後ろから見た画像を作ってください。
- この画像に、「静かに背中で語る、帽子とコートの余韻。」と縦書きで書いてください。
- ひとつ前の画像に「静かに背中で語る、帽子とコートの余韻。」を英訳して書いてください。
出来上がった画像から以下のことが分かる。

- 人物の姿勢や顔は同じままである。背景色も一貫している。
- 洋服の着こなしや帽子の被り方、後ろからの描画も自然である。空間把握能力が高そうである。
- 日本語のレンダリング能力は残念な結果になっている(左図参照)。
- 英訳「The lingering essence of hat and coat,Speaking silently from the back.」が適切かどうかは分からないが、そのレンダリングに問題はない。
- コートの色が異なる点、コートがダブルになっている点は残念である。
ChatGPT5
次に、ChatGPT5が生成した画像を示す。

使用したプロンプトは先と同じである。これらを見ると、以下のことが分かる。

- 人物の顔と姿勢が変わる。背景色も変わり、一貫性がない。
- 洋服の着こなしは自然だが、帽子が浮いている。(②)。
- 日本語のレンダリング能力はNano Bananaより良い(左図参照:余韻の「韻」が少しおかしいが)。
- 英訳「Speaking volumes in stillness — the hat and coat’s afterglow.」の正しさは置いておいて、そのレンダリングに問題はない。
- コートの形状は元画像に忠実であるが、色は少しずつ異なる。
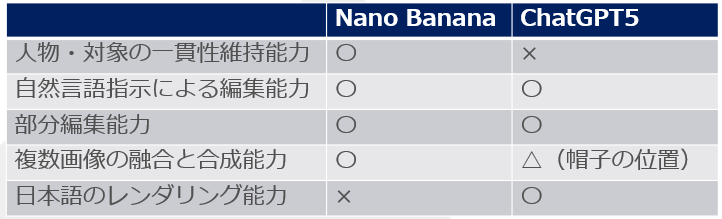
サンプル1の比較結果
主観的な評価となるがおおよそ以下の通りだろう。
サンプル2
Nano Banana
Nano Bananaの結果は以下の通り。

使用したプロンプトは以下の通り。
- この画像(上図の左上、著作者:freepik)の背景をクリスマス仕様にしてください。
- 猫にサンタクロースの衣装を着せてください。
- 背景右側に「メリークリスマス」という文字を入れてください。
- 猫にサンタクロースの白いひげをつけてください。
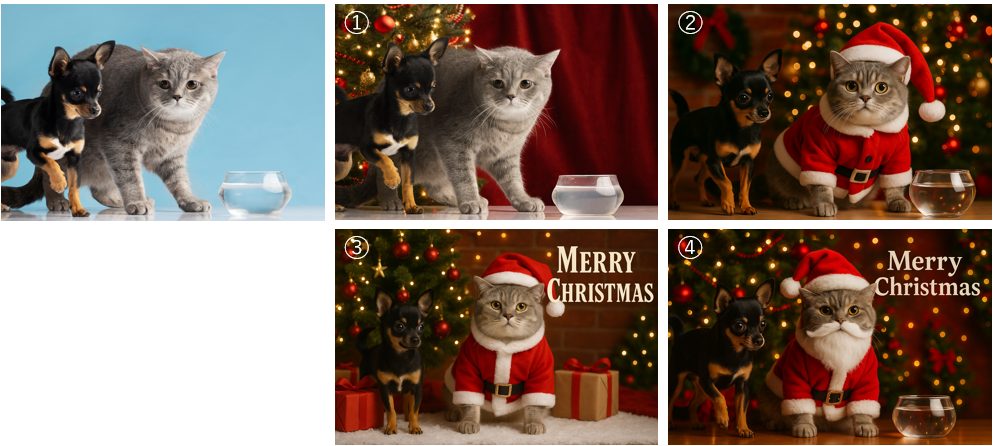
生成画像から以下のことが分かる。
- 猫と犬は同じままである。
- ①以降で背景は同じまま。
- ②以降で帽子は同じまま。
- コップも存在し続ける。①でコップの上面が白くなり、それ以降はこの状態が維持される。
- 「メリークリスマス」が「メリータリススス」になる。
ChatGPT5
次に、ChatGPTが生成した画像を示す。
プロンプトは先と同じである。生成画像から以下のことが分かる。
- ②以降は猫と犬の一貫性がなくなる。
- ③でコップが消えるが④で復活する。
- 帽子は変わり続ける。
- 背景は変わり続ける。
- 「メリークリスマス」は勝手に英訳される。
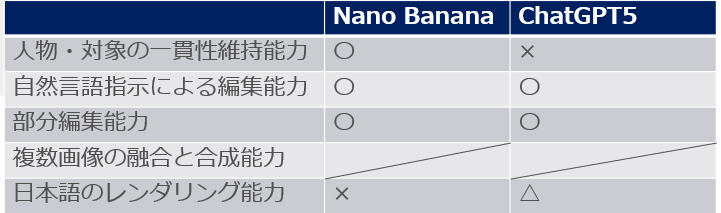
サンプル2の比較結果
主観的な評価となるがおおよそ以下の通りだろう。
まとめ
Nano Bananaの主な特徴とされる以下の4つについては概ねその通りであった。
- 人物・対象の一貫性維持能力(対象物の顔や姿勢は同じまま維持される)
- 自然言語指示による編集能力(背景を変える)
- 部分編集能力(ひげを付ける)
- 複数画像の融合と合成能力(別画像の服を着せる、帽子を被せる)
元画像をベースに加工を追加していくのであれば、元画像からの一貫性が維持されるNano Bananaの方が良い。ただし、日本語のレンダリング能力は弱いことに注意が必要だ。