

はじめに
これまで、GPT4oを用いた画像の異常検知や顔認証の簡単な検証を行ってきた。今回は、固有表現抽出を試してみる。
固有表現抽出とは
固有表現抽出(Named Entity Recognition:NER)とは、テキストから特定の種類の情報(固有表現)を自動的に識別し抽出する自然言語処理の手法である。固有表現には通常、次のような種類が含まれる。
Ginzaを用いた固有表現抽出
最初に、固有表現抽出を行うPythonライブラリ「GINZA」を紹介する。リンク先の説明に従いインストールを行ったあと以下を実行すれば良い。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
nlp = spacy.load("ja_ginza_electra") # 固有表現の抽出 # extract_entities(text_6, output_path_6, nlp) doc = nlp( "2024年のオリンピックはパリで開催される予定であり、" "多くの選手がフランスに集まることになる。" "昨年の東京オリンピックで金メダルを獲得した山田太郎も出場を目指している。" ) # 固有表現抽出 for ent in doc.ents: print( ent.text + ", " # 固有表現のテキスト自体 + ent.label_ + "," # 固有表現のラベル(人名、地名、組織名など) + str(ent.start_char) + "," # 固有表現の開始位置(文字数) + str(ent.end_char) ) # 固有表現の終了位置(文字数) |
7行目から9行目にかけて与えた文章が固有表現を抜き出す文章である。出力は以下の通り。
|
1 2 3 4 5 6 7 |
2024年, Date,0,5 オリンピック, Conference,6,12 パリ, City,13,15 フランス, Country,33,37 東京オリンピック, Game,50,58 金メダル, Natural_Phenomenon_Other,59,63 山田太郎, Person,68,72 |
各行は、<固有表現>, <ラベル>, <固有表現の先頭の文字番号>, <固有表現の末尾の文字番号>から成る。ラベルの種類は拡張固有表現階層定義に記載されている。これを見ると、かなり細かい分類であることが分かる。ところで、上の「金メダル」のラベルが「自然現象_その他」になっているのは意味不明だ。
GPT4oを用いた固有表現抽出
GPT4oを使う場合は、以下のようにするだけである。与えた文章は先と同じものである。
 こちらの「金メダル」には「賞」というラベルが割り当てられている。こちらの方が妥当である。
こちらの「金メダル」には「賞」というラベルが割り当てられている。こちらの方が妥当である。
比較
いくつかの文章を与えて、GINZAとGPT4oによる固有表現抽出を行ってみたが、ほぼ同じ結果であり面白くない。そこで、少し昔の小説の一節を与えてみる。
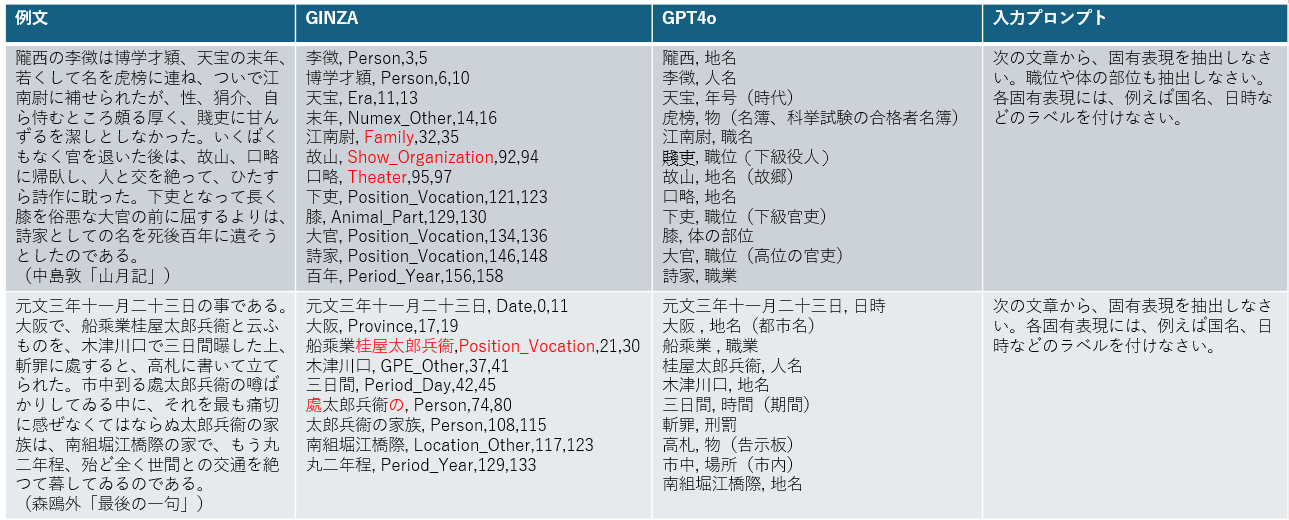
GINZAの方にいくつかおかしな部分がある(赤で示した部分)。一方で、GPT4oの方におかしな箇所はない。上段の例にてGPT4oが「虎榜」の意味を指摘しているのは流石である。
GPT4oによる履歴書の読み取り
最後に、GPT4oに履歴書(PDF)を与えて、固有表現抽出した結果を示す。

結果は以下の通り。

まとめ
今回は、固有表現抽出と呼ばれる自然言語処理の1ジャンルをGPT4oを用いて実現してみた。かなりの精度で固有表現を検出できることが分かった。最近、o1-previewやo1-miniに引き続き、o1とo1 proが公開された。ますます賢くなります。