

はじめに
はじめまして、エンジニアのせーさんです。
2020年12月上旬にAWS LambdaのパッケージフォーマットとしてDockerコンテナイメージが追加されました。
Lambda好きとしては夢が広がるアップデートなので、今回は使用感を確認するためにMeCab + NEologdで構築した形態素処理を行うWeb APIを構築してみました。
※ 本記事では以降 Lambda with Container Image と表記します。
※ 執筆時点で対応しているリージョンは以下になります。
米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、アジアパシフィック (東京)、アジアパシフィック (シンガポール)、欧州 (アイルランド)、欧州 (フランクフルト)、南米 (サンパウロ)
この記事のまとめ
- AWS LambdaでDockerコンテナが利用できるようになった
- 1GBの辞書データを持つ形態素解析処理をLambdaで構築してみた (コードもあるよ)
- Lambdaの守備範囲が増えサーバレス化の恩恵を受けやすくなった
LambdaでMeCab+NEologdな形態素解析処理を構築
昨年開発したとあるプロダクトにて外部サービスからWebHookで呼び出して連携する機能をLambda+API Gatewayを利用して構築しており、その中でテキスト解析処理のためMeCab+NEologdを利用した形態素解析処理を行っています。
結論としては辞書データを保存したEFSをLambdaにマウントする方式で構築してサービスインしたものの、環境構築やメンテナンスの手間に難があるなどの課題を現在進行系で抱えています。
上記課題をLambda with Container Imageで解決できるのか検証するため、そして何よりブログのネタにするために実際に試してみました。
Lambdaのファイルサイズ制限
外部ライブラリに依存する処理をLambdaで実現しようとした場合に考慮が必要な要素の一つにアップロードファイルのサイズ制限があります。手法とサイズ制限、および、個人的な感想をまとめるとこんな感じかと思います。Lambda with Container Imageにより選択肢が増えました。
| 手法 | サイズ制限 | 備考/所感 | サポート開始時期 |
|---|---|---|---|
| コンソールからアップロード | 3MB | 軽量処理は当然これで | |
| ZIP圧縮してアップロード | 50MB (ZIP圧縮状態) |
手軽だがサイズが心もとない | |
| Lambda Layers | 250MB (解凍後) |
正直サイズ制限が中途半端 読み込みに時間がかかるのもイマイチ |
2018.11~ |
| EFS(Elastic File System)をマウント | 実質無制限 | EFSをマウントするためVPC Lambdaになるのが面倒 EFSの用意も面倒 |
2020.6~ |
| Lambda with Container Image | 10GB (イメージサイズ) |
new !! | 2020.12~ |
ちなみにLambda with Container Imageによるメリットにはサイズ制限以外もりますが、今回は主にサイズ制限に着目しています。
LambdaでMeCabを利用する場合の課題
LambdaでMaCabを利用しようとした場合にファイルサイズ制限の影響を受けるのが辞書ファイルです。
MeCab本体のサイズはそこまで大きくないのですが、辞書にNEologdを利用するとビルド済みのバイナリデータのサイズが1GBを超えてきます。
ビルド時のオプションで登録単語数を減らしても700MB程度のバイナリデータになります。
1GBのバイナリデータとなるとLambda Layersのサイズ制限である250MBを軽く超えるため、今まではEFSを利用して解決するしかありませんでした。
といってもLambdaにEFSがマウント可能になったのが2020年6月なので「そんな処理はLambdaでやることじゃねぇ、素直にEC2かECSを使えよ。」という感じだった訳です。
でもLambdaを始めとしたサーバレスの便利さ、特にメンテナンス性を一度味わってしまうとEC2などを極力避ける気持ち、分かりますよね?ということで、いままではEFSを利用して構築していました。
さて、2020年6月にサポート開始されたEFSマウントを利用することでLambdaは実質無制限の容量を手にした訳ですが、利用するにあたって大きな制約事項がありました。
「VPC Lambdaでなければいけない。」という制約です。
EFSがVPC内に存在するネットワークファイルストレージ(NAS)であるため、EFSに接続するには接続先のLambdaもそのVPCのプライベートサブネットに接続できる必要があります。
したがってLambdaに対してVPCのネットワーク設定をする必要があり、当然セキュリティ面の考慮などネットワーク設計もVPC Lambdaの利用について検討・反映させる必要があります。
VPCの設定をすることでEFSのファイルシステムをVPC Lambdaにマウントするまでできた訳ですが、次はマウントするファイルシステムに事前にライブラリファイルを保存しておく必要があります。
そのため事前に専用のEC2インスタンスなどからライブラリファイルを保存しておく必要があり、環境構築にも、ライブラリの変更にもどうしても一手間かかってきます。
環境(本番環境用、ステージング環境用、開発環境用など)毎にEFSのファイルシステムを用意するなど運用面を考慮するのもまた一苦労です。
Lambdaのサーバレスとしての恩恵を受けるために支払うコストとしては少し高いのではないかと思います。
Lambda with Container Imageで構築
ようやく本題に入ります。
EFSほどのファイルサイズは扱えませんが、Lambda Layersよりは十分に大きいサイズを扱えるLambda with Container ImageでMeCab+NEologd環境を構築していきいます。
環境と手順
Lambdaを扱う方法はコンソールを始めいくつかの選択肢がありますが個人的に慣れている Serverless Framework を、同じ理由でハンドラーの記述には Python3 を利用していきます。
手順はこんな感じ
- Serverless Frameworkプロジェクトの作成
- ハンドラー処理の実装
- Dockerfile作成とDockerイメージのビルド
- ECRのDockerリポジトリ作成とイメージの登録
- AWSへのデプロイと動作確認
ちなみにソースコードはGithubにて公開しているのでご自由にご利用ください。
質問や改善ポイントのご指摘などがありましたらブログのコメント欄にいただけると嬉しいです。
環境情報
- 端末/OS: MacBook Pro (16-inch, 2019) / macOS Big Sur
- Python: 3.8.5
- Docker: 20.10.0 (Docker Desktop for Mac 3.0.3)
- Node.js: v12.16.1 (npm 6.14.8)
- AWS CLI: 2.1.13
- Serverless Framework: 2.16.1
また事前にServerless Framework用のIAMユーザーを作成しておきます。
- 検証用のためポリシーは AdministratorAccess をアタッチ
aws configureでローカル端末にプロファイル登録済み
Serverless Frameworkプロジェクトの作成
とりあえずビールの感覚(コロナ禍で忘れ気味)でServerless Frameworkのバージョンを確認します。
|
1 2 3 4 5 6 |
$ sls -v Framework Core: 2.16.1 Plugin: 4.3.0 SDK: 2.3.2 Components: 3.4.3 |
テンプレートからプロジェクト作成
sls createコマンドでaws-python3をベースにプロジェクトpymecab-lambda-containerを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ sls create -t aws-python3 -n pymecab-lambda-container -p pymecab-lambda-container Serverless: Generating boilerplate... Serverless: Generating boilerplate in "/Users/hoge/Develop/blog/pymecab-lambda-container" _______ __ | _ .-----.----.--.--.-----.----| .-----.-----.-----. | |___| -__| _| | | -__| _| | -__|__ --|__ --| |____ |_____|__| \___/|_____|__| |__|_____|_____|_____| | | | The Serverless Application Framework | | serverless.com, v2.16.1 -------' Serverless: Successfully generated boilerplate for template: "aws-python3" |
成功して指定ディレクトリにファイルが3つ作成されているのを確認してプロジェクト作成完了です。
|
1 2 3 4 5 6 7 8 |
$ ll pymecab-lambda-container/ total 12K drwxr-xr-x 5 hoge staff 160 2020-12-22T21:58:16 ./ drwxr-xr-x 3 hoge staff 96 2020-12-22T21:58:16 ../ -rw-r--r-- 1 hoge staff 192 2020-12-22T21:58:16 .gitignore -rw-r--r-- 1 hoge staff 497 2020-12-22T21:58:16 handler.py -rw-r--r-- 1 hoge staff 3.2K 2020-12-22T21:58:16 serverless.yml |
プロジェクト設定ファイルの修正
自動生成されたserverless.ymlから有効部分を抜粋するとこんな感じになっていると思います。
|
1 2 3 4 5 6 7 8 9 10 11 |
service: pymecab-lambda-container frameworkVersion: '2' provider: name: aws runtime: python3.8 functions: hello: handler: handler.hello |
Dockerコンテナを利用するための設定変更をしていきます。設定したものがこちらになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
service: pymecab-lambda-container frameworkVersion: '2' provider: name: aws runtime: python3.8 stage: dev region: ${self:custom.env.region} timeout: 30 custom: env: ${file(./config/env.yml)} functions: parse: image: "${self:custom.env.accountID}.dkr.ecr.${self:custom.env.region}.amazonaws.com/\ ${self:custom.env.repository}@${self:custom.env.digest}" events: - http: path: mecab/parse method: post |
また環境に依存する設定値を./config/env.ymlに切り出しました。上記serverless.ymlのcustom:の部分で読み込んでいます。
今回に限っては「後で記事のマスク処理が面倒」という思いが主な理由のため「stage毎に設定ファイルを切り替える」様な設定は組み込んでいません。
|
1 2 3 4 |
accountID: 000000000000 region: ap-northeast-1 repository: example digest: |
accountID, regionはAWS環境に合わせて設定します。
repositoryはECRのリポジトリ名として後ほど利用します。好みとセンスで命名してください。
digestはECRにDockerイメージをpushしたときに生成されるハッシュ値のため、現時点では未指定になります。
利用するpythonライブラリを設定
requirements.txtにDockerイメージのビルド時にpip installするためのpythonライブラリを設定します。
今回はMaCabとPythonをつなぐ必要があるためmecab-python3のみ設定しておきます。
|
1 |
mecab-python3 |
※ PythonからMeCabを利用する方法としては他にnatto-pyやfugashiがありますが、辞書の指定方法がシンプルなため今回はmecab-python3を利用しています。
ハンドラー処理の実装
プロジェクト作成時に出力されたhandler.pyを削除してプロジェクト直下にapp.pyを新規作成します。
ファイル名は筆者の好みです。
簡単な仕様
- NEologdを辞書として利用するMeCabのTaggerを分かち書きモードで初期化
- リクエストbodyに送られてきた文字列を形態素解析
- 解析結果から表示に不要な’BOS’および’EOS’を除外
- 解析した結果を配列化して返却
今回はこんな感じに用意しました。
API Gateway経由で利用想定のため、リクエストとレスポンスはそれに合わせて処理しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import json import MeCab neologd_tagger = MeCab.Tagger( '-O wakati ' '-r /dev/null ' '-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd') def lambda_handler(event, context): node = neologd_tagger.parseToNode(event['body']) result = [] while node: if not node.feature.startswith('BOS/EOS'): result.append(node.feature) node = node.next return { "statusCode": 200, "headers": { "Content-Type": "application/json", "Access-Control-Allow-Origin": "*" }, "body": json.dumps(result), "isBase64Encoded": False } |
Dockerfile作成とDockerイメージのビルド
Lambdaで利用するDockerのコンテナイメージを作成していきます。
AWSからLambda用のベースイメージが提供されているのでそちらを使っていきます。
@see https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/runtimes-images.html
AWS ECRの接続設定とベースイメージの取得
次のコマンドでAWS ECRのパスワードを取得しつつ、dockerコマンドでECRのリポジトリにログインします。 以後のコマンド、および、コマンド実行結果にある{}表記は./config/env.ymlに指定する値と置き換えてください。
無事ログインに成功するとLogin Succeededと表示されます。
|
1 2 3 |
$ aws ecr get-login-password --region {region} | docker login --username AWS --password-stdin {accountID}.dkr.ecr.{region}.amazonaws.com Login Succeeded |
なお、Windows環境だと次のようになるそうです。(未検証)
|
1 |
(Get-ECRLoginCommand).Password | docker login --username AWS --password-stdin {accountID}.dkr.ecr.{region}.amazonaws.com |
次に確認も兼ねて今回利用するベースイメージをローカルに取得してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ docker pull public.ecr.aws/lambda/python:3.8 3.8: Pulling from lambda/python d519fd89485b: Pull complete 6460572f426b: Pull complete c18accecece0: Pull complete 03ac043af787: Pull complete 04f3d6691c40: Pull complete c5195ce15cfb: Pull complete Digest: sha256:313995d27e68d28fc879f28c24f3d13a185c083a1c41fef2d44afacfd03ff2dc Status: Downloaded newer image for public.ecr.aws/lambda/python:3.8 public.ecr.aws/lambda/python:3.8 |
Dockerfileの作成
Dockerfileを作成します。安直に ./Dockerfile に作っていきます。
MeCab、および、辞書のビルドに必要なライブラリと、各種ビルド & インストール、最後にハンドラー実行の設定を書いて完成です。
なお今回は検証目的のため1つのイメージにまとめています。
実際に運用する場合はステップ数を減らし、更にビルド部分と実行部分を分けることでイメージサイズを極力小さくすることをおすすめします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
FROM public.ecr.aws/lambda/python:3.8 # install build libs RUN yum groupinstall -y "Development Tools" \ && yum install -y which openssl # install mecab, ipadic, ipadic-neologd WORKDIR /tmp RUN curl -L "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE" -o mecab-0.996.tar.gz \ && tar xzf mecab-0.996.tar.gz \ && cd mecab-0.996 \ && ./configure \ && make \ && make check \ && make install \ && cd .. \ && rm -rf mecab-0.996* WORKDIR /tmp RUN curl -L "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM" -o mecab-ipadic-2.7.0-20070801.tar.gz \ && tar -zxvf mecab-ipadic-2.7.0-20070801.tar.gz \ && cd mecab-ipadic-2.7.0-20070801 \ && ./configure --with-charset=utf8 \ && make \ && make install \ && cd .. \ && rm -rf mecab-ipadic-2.7.0-20070801 WORKDIR /tmp RUN git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git \ && cd mecab-ipadic-neologd \ && ./bin/install-mecab-ipadic-neologd -n -a -y \ && rm -rf mecab-ipadic-neologd # setup python COPY ./requirements.txt /opt/ RUN pip install --upgrade pip && pip install -r /opt/requirements.txt # set function code WORKDIR /var/task COPY app.py . CMD ["app.lambda_handler"] |
Dockerfileを保存したらタグ付けしつつビルドしていきます。
各種ファイルのダウンロードとビルドを行うため時間がかかります。筆者の環境では4分弱かかりました。
|
1 2 3 4 5 6 7 |
$ docker build -t pymecab-lambda-container-dev ./ Sending build context to Docker daemon 89.09kB Step 1/15 : FROM public.ecr.aws/lambda/python:3.8 ...(中略)... Successfully built xxxxxxxx Successfully tagged pymecab-lambda-container-dev:latest |
ECRのDockerリポジトリ作成とイメージの登録
ECRリポジトリの新規作成
次のコマンドでECRに新しいプライベートリポジトリを作成します。
オプションの--image-scanning-configuration scanOnPush=trueでpush成功時に自動でスキャンするよう設定しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$ aws ecr create-repository --repository-name {repository} --image-scanning-configuration scanOnPush=true { "repository": { "repositoryArn": "arn:aws:ecr:{region}:{accountID}:repository/{repository}", "registryId": "{accountID}", "repositoryName": "{repository}", "repositoryUri": "{accountID}.dkr.ecr.{region}.amazonaws.com/{repository}", "createdAt": "2020-12-25T00:00:00+09:00", "imageTagMutability": "MUTABLE", "imageScanningConfiguration": { "scanOnPush": true }, "encryptionConfiguration": { "encryptionType": "AES256" } } } |
成功するとJSON形式でリポジトリ情報が返ってきます。
作成したDockerイメージをECRリポジトリに登録
ECRリポジトリ向けにタグ付けをおこない、ECRリポジトリに対してdocker pushします。
ここで実行するdocker pushは合計4GB程度のファイルアップロード処理になるためご注意ください。
成功するとdigestの値が取れるのでコピーしておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ docker tag pymecab-lambda-container-dev:latest {accountID}.dkr.ecr.{region}.amazonaws.com/{repository}:latest $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE {accountID}.dkr.ecr.{region}.amazonaws.com/{repository} latest yyyyyyyyyyyy 9 minutes ago 595MB pymecab-lambda-container-dev latest yyyyyyyyyyyy 9 minutes ago 595MB public.ecr.aws/lambda/python 3.8 zzzzzzzzzzzz 3 days ago 595MB $ docker push {accountID}.dkr.ecr.{region}.amazonaws.com/{repository}:latest The push refers to repository [{accountID}.dkr.ecr.{region}.amazonaws.com/{repository}] yyyyyyyyyyyy: Pushed ... (中略) ... zzzzzzzzzzzz: Pushed latest: digest: {digest} size: 3262 |
取得したdigestの値を設定ファイルに反映
./config/env.ymlの最終行に記述したdigestの値にECRリポジトリ登録時に取得したdigestの値を設定します。
これでLambdaで使うDockerイメージを特定するのに必要な情報が揃いました。
|
1 2 3 4 |
accountID: 000000000000 region: {region} repository: example digest: sha256:xxx #←ここに反映 |
AWSへのデプロイと動作確認
ここまででデプロイの準備が整ったのでsls deployコマンドでデプロイしていきます。
成功するとServerless: Stack update finished...のようなメッセージに合わせてデプロイ結果の情報が表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
$ sls deploy Serverless: Packaging service... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... .............. Serverless: Stack update finished... Service Information service: pymecab-lambda-container stage: dev region: {region} stack: pymecab-lambda-container-dev resources: 12 api keys: None endpoints: POST - https://{apiId}.execute-api.{region}.amazonaws.com/dev/mecab/parse functions: parse: pymecab-lambda-container-dev-parse layers: None Serverless: Removing old service artifacts from S3... |
動作確認
デプロイ結果の情報にあるendpoints:がAPI Gatewayでアクセス可能なメソッドとURLになります。
今回はPOSTする必要がありブラウザでの確認は難しいのでPostmanを使って確認していきます。
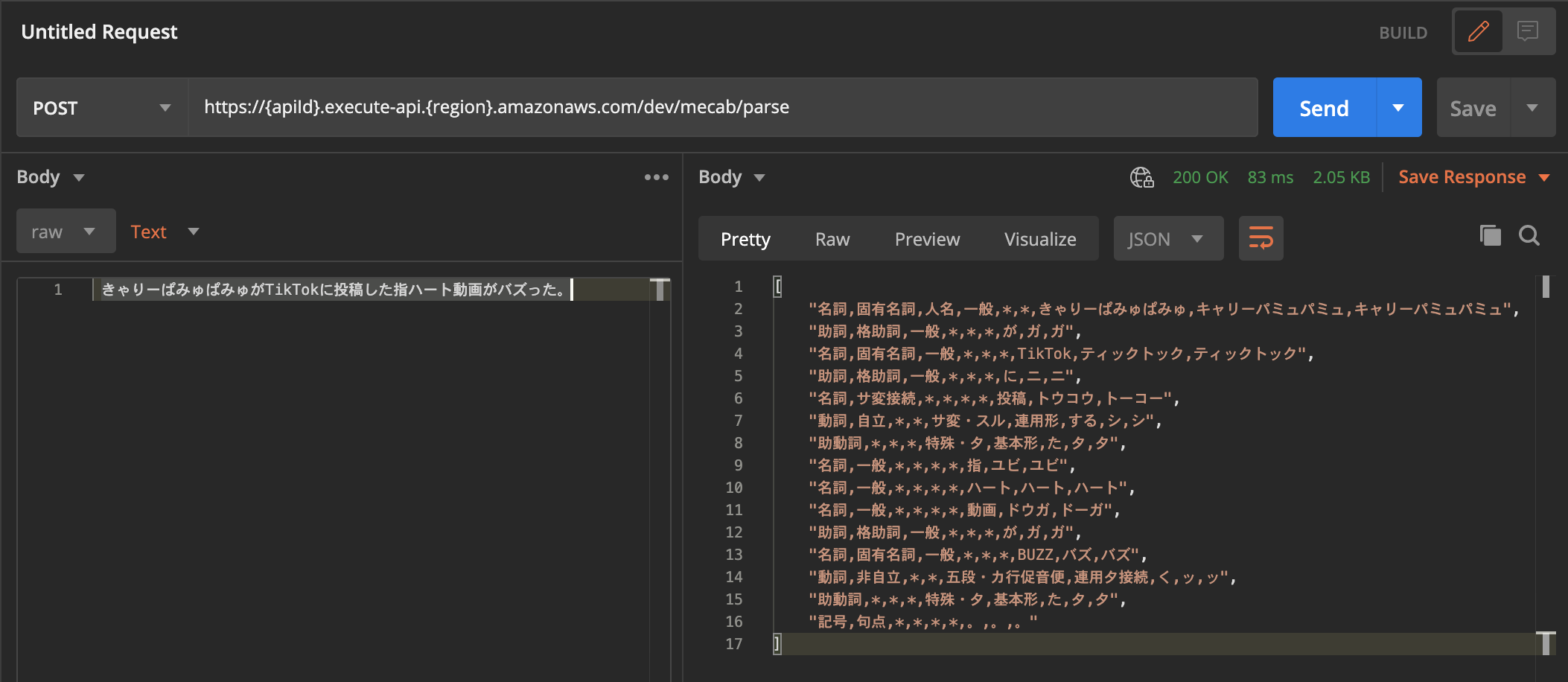
Postmanでの実行結果
さすが現代語が反映されているNEologdですね、定番のきゃりーぱみゅぱみゅはもちろんTikTokやバズるもそれっぽく解析できています。
指ハートは一般的過ぎる名詞の組み合わせなためか1単語にはなりませんでした。
これで無事にLambda with Container ImageでMeCab + NEologdを利用したAPIが構築できました!
おわりに
ここまで読んでいただきありがとうございます。
Lambda with Container ImageによってLambdaの可能性は大きく広がったと感じています。
ファイルサイズが数GB程度までであれば機械学習のモデルなどを利用した解析処理も簡単にLambda化できそうです。
それではまた次のブログで。
参考
https://aws.amazon.com/jp/blogs/news/new-for-aws-lambda-container-image-support/
https://www.serverless.com/blog/container-support-for-lambda